Learn how industry leaders are using ai in insurance underwriting to reduce their processing times and improve their risk assessment accuracy.




TL;DR
- Insurance underwriting delays usually begin long before risk evaluation starts. Carriers still depend heavily on PDFs, broker emails, scanned ACORD forms, and disconnected policy systems that force underwriters into manual intake and verification work.
- AI underwriting systems work as layered pipelines, not standalone models. OCR, document classification, retrieval systems, scoring models, and orchestration logic must all operate together before straight-through processing becomes reliable.
- Predictive underwriting models depend more on data quality and integration hygiene than algorithm selection. Production deployments fail when policy history, claims records, and third-party risk feeds remain inconsistent across legacy carrier systems.
- Retrieval systems have become operational controls inside underwriting workflows. Without grounded access to underwriting guidelines, policy filings, and jurisdiction-specific endorsements, language models can generate incorrect coverage interpretations with high confidence.
- Commercial underwriting still requires human escalation paths because many submissions fall outside standardized rule boundaries. High-value policies, specialty risks, and ambiguous coverage scenarios continue to depend on underwriter judgment and documented review trails.
- Regulatory pressure is moving underwriting AI away from black-box decisioning toward traceable workflow systems. Carriers now need explainability logs, model governance controls, bias testing procedures, and auditable escalation records tied directly to underwriting outcomes.
Why Insurance Underwriting Workflows Are Changing
Commercial underwriting teams still spend large parts of their day moving through PDFs, broker emails, inspection reports, and fragmented policy systems before a risk decision even begins. The operational problem is no longer model availability. It is workflow fragmentation, inconsistent data, and review pipelines that cannot keep up with submission volume.
Gartner notes that insurers are shifting from static rule engines toward predictive underwriting systems and external data enrichment, while Statista reports underwriting and operational efficiency among the largest AI investment areas in insurance. Discussions across Reddit underwriting communities reflect the same pressure: analysts describe spending hours reviewing submissions manually because existing systems cannot reliably classify documents, trace decisions, or handle exceptions without escalation queues.
Adopt AI frames this shift around orchestration across existing insurance infrastructure rather than standalone assistants, which mirrors how insurers are approaching deployment in practice. This article examines how AI underwriting systems process risk data, manage escalation workflows, integrate with legacy insurance platforms, and maintain explainability under regulatory pressure.
What Happens in Insurance Underwriting
Insurance underwriting is the process carriers use to evaluate risk before issuing a policy. Underwriters review information about a person, property, business, or asset to determine whether the insurer should accept the risk, what coverage terms apply, and how much premium should be charged. The process combines historical loss data, regulatory requirements, actuarial models, and policy guidelines to estimate the likelihood and financial impact of future claims. In personal insurance lines, including auto or homeowners coverage, underwriting decisions often rely on standardized data fields and predictable risk patterns. Commercial underwriting is more variable because submissions can include custom coverage structures, industry-specific exposures, financial statements, inspection reports, and broker-provided documentation spread across multiple formats.
Most underwriting workflows still depend on fragmented operational systems built long before modern AI pipelines existed. A single submission may move through broker portals, email attachments, PDF forms, claims databases, policy administration systems, and third-party risk tools before a decision is made. Underwriters spend large portions of their day reviewing incomplete records, validating extracted data, checking policy exclusions, and escalating exceptions rather than evaluating risk directly. AI systems are being introduced into this environment to reduce intake bottlenecks, classify documents, extract structured data, assist with risk scoring, and route submissions through approval or escalation paths without replacing human review on high-severity decisions.
Why Insurance Underwriting Workflows Are Breaking Under Manual Review Pressure
The infrastructure underneath most underwriting operations, built around manual review cycles, fragmented systems, and static decision rules, hasn't kept pace with how fast brokers, distribution partners, and policyholders now expect decisions. Three connected failure points drive the breakdown: where underwriters' time actually goes, why existing rule engines fail when submissions get complicated, and what faster quote turnaround now means for competitive positioning.
Underwriters Spend More Time Collecting Data Than Evaluating Risk
The job title says "underwriter," but the working reality looks a lot more like a document librarian. According to Capgemini's 2024 World Property and Casualty Insurance Report, between 41% and 43% of commercial and personal line underwriters' time goes to administrative activities like data entry and record keeping, while only 32% to 33% is dedicated to core activities such as risk assessment, premium calculation, and book management.
Accenture's research puts it even more plainly: just 30% of an underwriter's time is spent on risk analysis and generating quotes, and two-thirds say their workload has increased as new technology tools were introduced, with non-core administrative tasks remaining largely untouched. A single commercial P&C submission can arrive as a mix of ACORD forms, broker cover notes, prior loss runs in PDF, inspection reports, and financials scanned from paper.
The underwriter, or more often a junior analyst, manually pulls fields from each document, maps them into the policy admin system, flags inconsistencies, and chases missing data before any actual risk judgment can begin.
Legacy Rule Engines Fail When Submission Complexity Increases
Rule-based underwriting systems work well for personal auto, homeowners, and straightforward small commercial lines, where submissions arrive in known formats and rules evaluate discrete fields against defined thresholds. The architecture breaks down the moment submission complexity outgrows the rules. The Earnix 2024 Industry Trends report found that nearly 75% of insurers have hundreds of rules embedded in their underwriting systems, with 18% managing thousands, and in the most complex environments, 50% of executives said changes were necessary but couldn't implement them.
Fractal Analytics' analysis of commercial underwriting operations found that cases which nearly fit the underwriting appetite are escalated precisely because the system cannot express conditional approvals, while overly permissive systems approve risks without explicit safeguards, creating downstream leakage. Commercial lines submissions, specialty risks, and anything in grey territory between standard and non-standard appetite get pushed to manual review by default, not because they're genuinely complex, but because the rule engine has no middle lane.
Faster Quoting Changes Competitive Positioning Across Insurance Markets
In commercial markets, brokers typically submit the same risk to multiple carriers simultaneously and place with whoever responds first with an acceptable quote. Slow turnaround isn't just an operational inconvenience; it's a policy that never gets written. A 2024 benchmark study by Hyperexponential found it takes approximately eight days from submission to quote and another 12 days from quote to bind in commercial P&C markets on average, while McKinsey's P&C Underwriting Transformation analysis found that digitized underwriting can improve loss ratios by three to five points and lift new-business premiums by ten to 15 percent.
Hiscox has documented a 99.4% reduction in quote cycle time for London Market specialty lines, compressing turnaround from three days to approximately three minutes while preserving underwriter control over final pricing, and that is a production result from a major specialty insurer, not a pilot metric. Carriers gaining ground are separating the high-volume, low-complexity portion of their submission book from cases that require specialist judgment, then automating the first category aggressively while investing underwriter capacity in the second.
What Are the Regulatory Implications of AI in Insurance?
This is where the conversation gets critical, and where many insurers are underinvesting. The regulatory framework for AI in insurance is tightening rapidly across multiple jurisdictions:
- NAIC Model Bulletin on AI (2023–2026): The National Association of Insurance Commissioners issued guidance requiring insurers to manage AI risks throughout the lifecycle, with emphasis on transparency, fairness, and accountability. Multiple states have adopted or are adopting these guidelines into law.
- EU AI Act: Effective in phases through 2026, the EU AI Act classifies insurance underwriting and claims processing AI as "high-risk" systems, requiring rigorous documentation, human oversight, bias testing, and explainability.
- State-Level Regulations: Colorado's SB 21-169 requires insurers to test for unfair discrimination in AI-driven decisions. Connecticut, New York, and several other states are implementing similar requirements. The trend is clear: algorithmic accountability is becoming law.
- Model Risk Management: Regulators increasingly expect insurers to maintain model inventories, conduct regular validation, and demonstrate that AI decisions can be explained to policyholders and regulators alike.
How AI Underwriting Systems Process Risk Data Across Insurance Pipelines
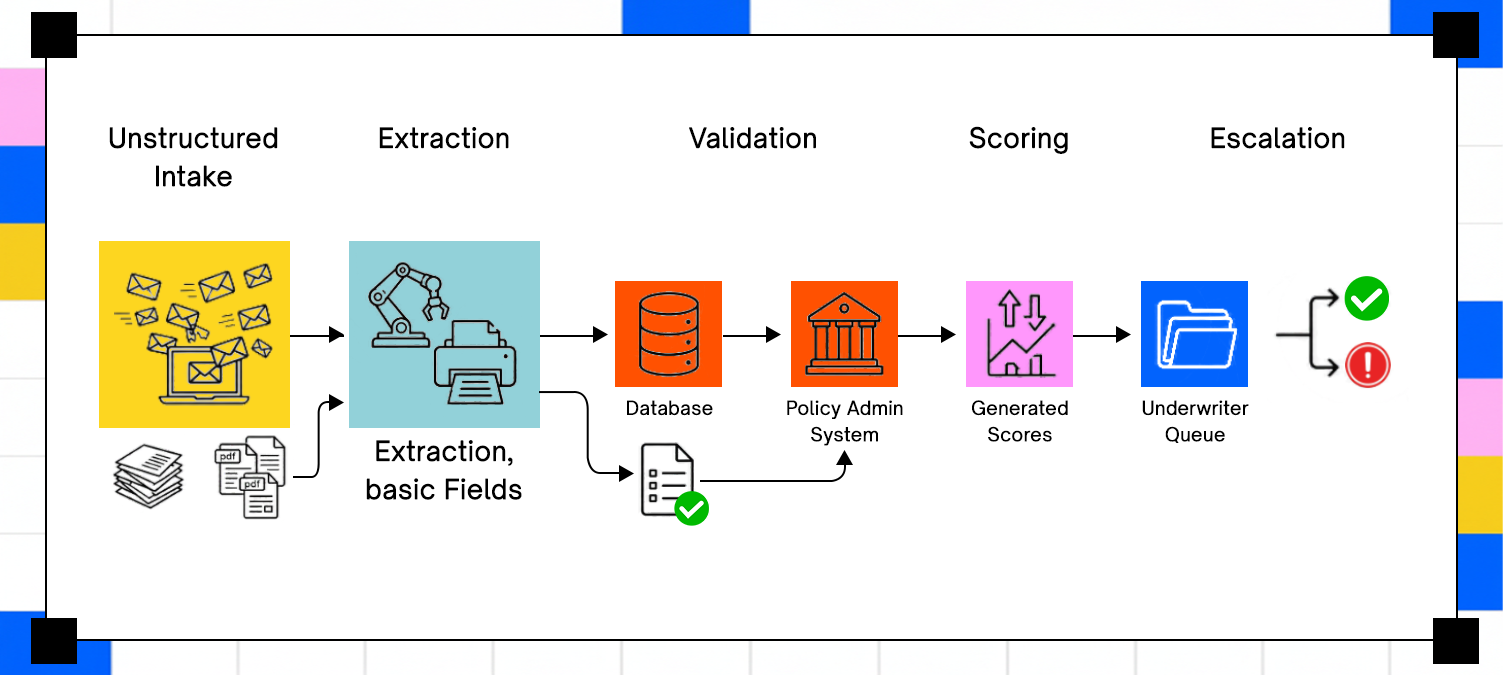
Moving from a manual review-heavy workflow to an AI-assisted one is a sequence of interconnected engineering and data problems, each of which has to work before the next one can. The pipeline has three functional layers: document ingestion, predictive scoring, and decision orchestration. A weakness in any one of them undermines the accuracy of everything downstream.
Document Ingestion Pipelines Convert Unstructured Files Into Risk Signals
Submissions arrive as PDFs, scanned images, Excel attachments, email bodies, and occasionally fax-to-email conversions of handwritten forms. The ingestion layer combines optical character recognition (OCR), document classification, and natural language processing (NLP) into a sequential pipeline: OCR converts image or scanned formats to machine-readable text, classification routes each document type to the appropriate extraction logic, and NLP identifies and extracts specific entities including named insureds, coverage limits, prior claims, occupancy codes, and financial figures.
Carriers deploying OCR, NLP, and workflow automation report 30% to 40% cost reductions and faster broker turnaround, with document intelligence platforms converting PDFs into structured data in minutes rather than hours. Confidence scoring is the mechanism that keeps imperfect extractions from contaminating downstream decisions: fields below a defined certainty threshold get flagged for human review rather than passed automatically into the risk scoring layer, with threshold calibration being the difference between a reviewer buried in false positives and a model quietly fed bad data.
# Install Tesseract OCR engine
!sudo apt-get update
!sudo apt-get install tesseract-ocr
# Install pytesseract
!pip install pytesseract
import pytesseract
from PIL import Image
import re
# Load insurance document image
image = Image.open("insurance_application.png")
# OCR extraction
raw_text = pytesseract.image_to_string(image)
print("Extracted Text:")
print(raw_text)
# Extract applicant information
name_match = re.search(r"Applicant Name:\s*(.*)", raw_text)
policy_match = re.search(r"Policy Type:\s*(.*)", raw_text)
income_match = re.search(r"Annual Income:\s*\$?(\d+)", raw_text)
structured_data = {
"applicant_name": name_match.group(1) if name_match else None,
"policy_type": policy_match.group(1) if policy_match else None,
"annual_income": int(income_match.group(1)) if income_match else None
}
print("\nStructured Underwriting Data:")
print(structured_data)
# Escalation logic
if structured_data["annual_income"] is None:
print("Escalate: Missing Financial Information")
else:
print("Document Ready For Underwriting Review")
This example uses Tesseract OCR to extract raw text from an insurance application image, then applies regular expressions to identify underwriting fields including applicant name, policy type, and annual income. The final escalation check simulates a common underwriting control where incomplete financial data automatically routes the submission into a manual review queue instead of continuing through straight-through processing.
NOTE: You should have the PNG to get the desired output. You can use this to generate one.
from PIL import Image, ImageDraw, ImageFont
def create_insurance_application_image(filename="insurance_application.png", width=800, height=600):
# Create a blank white image
img = Image.new('RGB', (width, height), color = 'white')
d = ImageDraw.Draw(img)
try:
# Try to load a default font, fall back if not available
font = ImageFont.truetype("arial.ttf", 24)
font_bold = ImageFont.truetype("arial.ttf", 32)
except IOError:
font = ImageFont.load_default()
font_bold = ImageFont.load_default()
# Draw title
d.text((50, 50), "Insurance Application Form", fill=(0,0,0), font=font_bold)
# Draw fields and values
d.text((50, 150), "Applicant Name: John Doe", fill=(0,0,0), font=font)
d.text((50, 200), "Policy Type: Life Insurance", fill=(0,0,0), font=font)
d.text((50, 250), "Annual Income: $75000", fill=(0,0,0), font=font)
d.text((50, 300), "Date of Birth: 01/01/1990", fill=(0,0,0), font=font)
d.text((50, 350), "Address: 123 Main St, Anytown, USA", fill=(0,0,0), font=font)
# Save the image
img.save(filename)
print(f"Generated '{filename}' successfully.")
# Generate the image
create_insurance_application_image()

Risk Scoring Models Combine Historical Loss Data With External Signals
Once the ingestion layer produces structured fields, predictive scoring models evaluate the submitted risk against historical loss data, apply feature engineering to generate risk-relevant signals, and produce a numeric output quantifying expected loss exposure. The inputs go well beyond what appears in the submission: geospatial data layers inform property assessments with flood zone maps and wildfire probability scores, telematics feeds inform personal and commercial auto pricing with observed driving behavior, and third-party commercial databases contribute financial health signals, industry loss benchmarks, and supply chain exposure data.
Predictive models reflect market conditions from their training period; when those conditions shift, whether from a catastrophe season, an economic change, or a regulatory update, carriers need monitoring infrastructure that tracks model performance against actual loss outcomes continuously and triggers retraining before drift degrades pricing quality.
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
# Sample underwriting dataset
data = pd.DataFrame([
{
"age": 34,
"annual_income": 85000,
"credit_score": 710,
"prior_claims": 1,
"property_risk_score": 42,
"approved": 1
},
{
"age": 58,
"annual_income": 42000,
"credit_score": 590,
"prior_claims": 5,
"property_risk_score": 88,
"approved": 0
},
{
"age": 45,
"annual_income": 120000,
"credit_score": 740,
"prior_claims": 0,
"property_risk_score": 20,
"approved": 1
},
{
"age": 51,
"annual_income": 65000,
"credit_score": 610,
"prior_claims": 4,
"property_risk_score": 75,
"approved": 0
}
])
X = data.drop("approved", axis=1)
y = data["approved"]
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.25,
random_state=42
)
model = GradientBoostingClassifier(
n_estimators=150,
learning_rate=0.05,
max_depth=3,
random_state=42
)
model.fit(X_train, y_train)
predictions = model.predict(X_test)
print(classification_report(y_test, predictions))
# New underwriting application
new_application = pd.DataFrame([
{
"age": 39,
"annual_income": 97000,
"credit_score": 690,
"prior_claims": 2,
"property_risk_score": 48
}
])
approval_probability = model.predict_proba(new_application)[0][1]
print(f"Approval Probability: {approval_probability:.2f}")
if approval_probability > 0.80:
print("Decision: Straight-Through Approval")
elif approval_probability > 0.55:
print("Decision: Manual Underwriter Review")
else:
print("Decision: Reject")
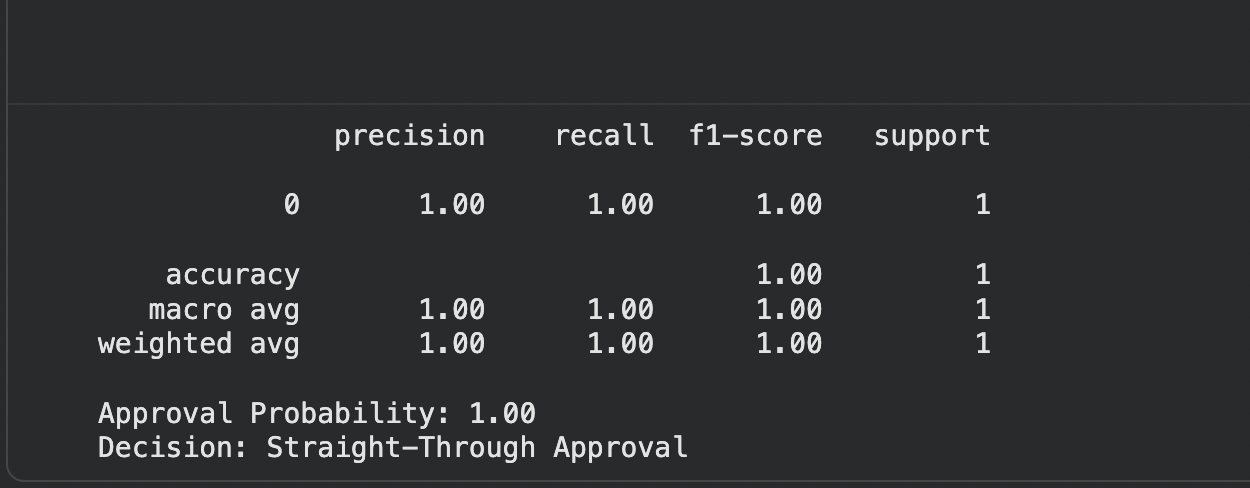
This example trains a Gradient Boosting classifier on a simplified underwriting dataset containing applicant financial and risk attributes. The model generates an approval probability score for a new submission, then routes the application into approval, manual review, or rejection paths based on predefined confidence thresholds, which mirrors how many underwriting triage systems operate in production environments.
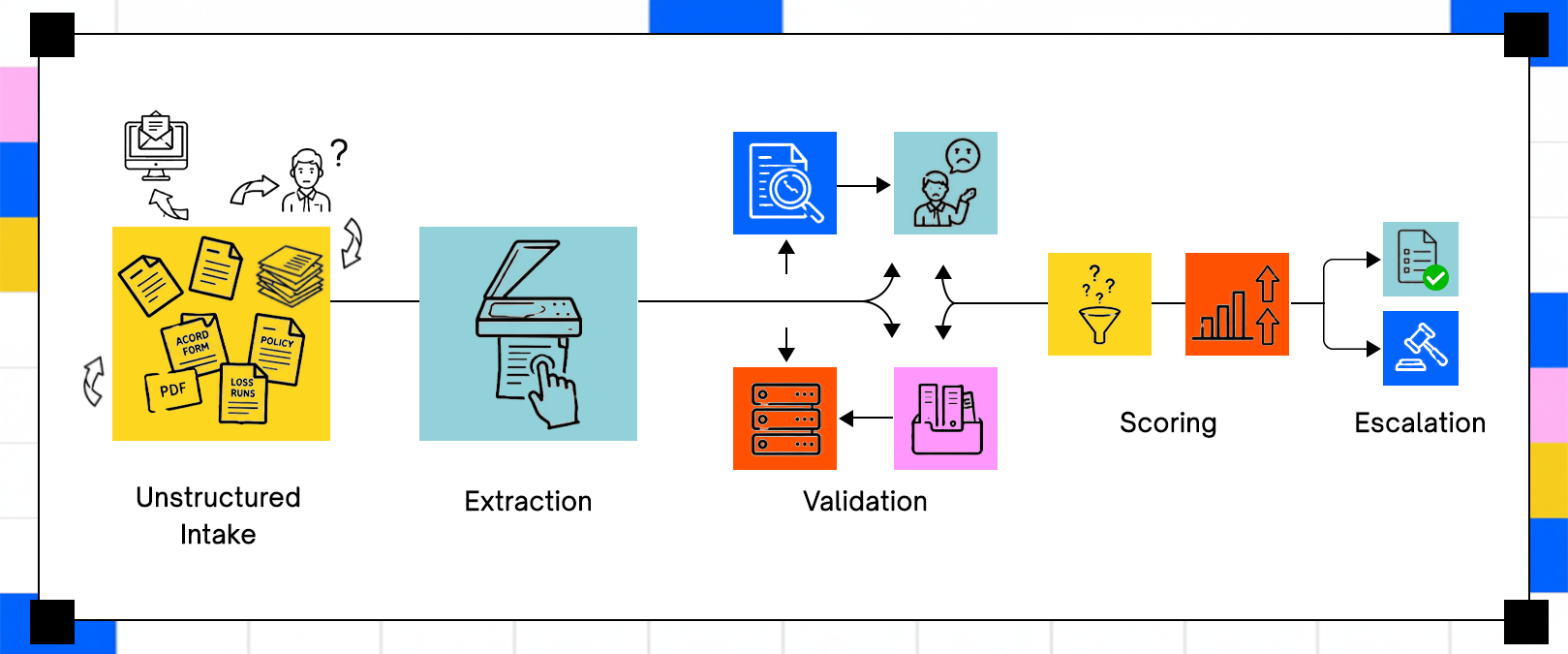
Decision Orchestration Systems Route Cases Based On Confidence Thresholds
Decision orchestration translates a risk score into an action: approve straight-through, send to a review queue with pre-populated fields for an underwriter to validate, escalate to a specialist, or decline with a documented rationale. Submissions that score clearly within the carrier's appetite on all dimensions proceed to straight-through processing; those scoring near a boundary or with low-confidence field extractions route to a review queue.
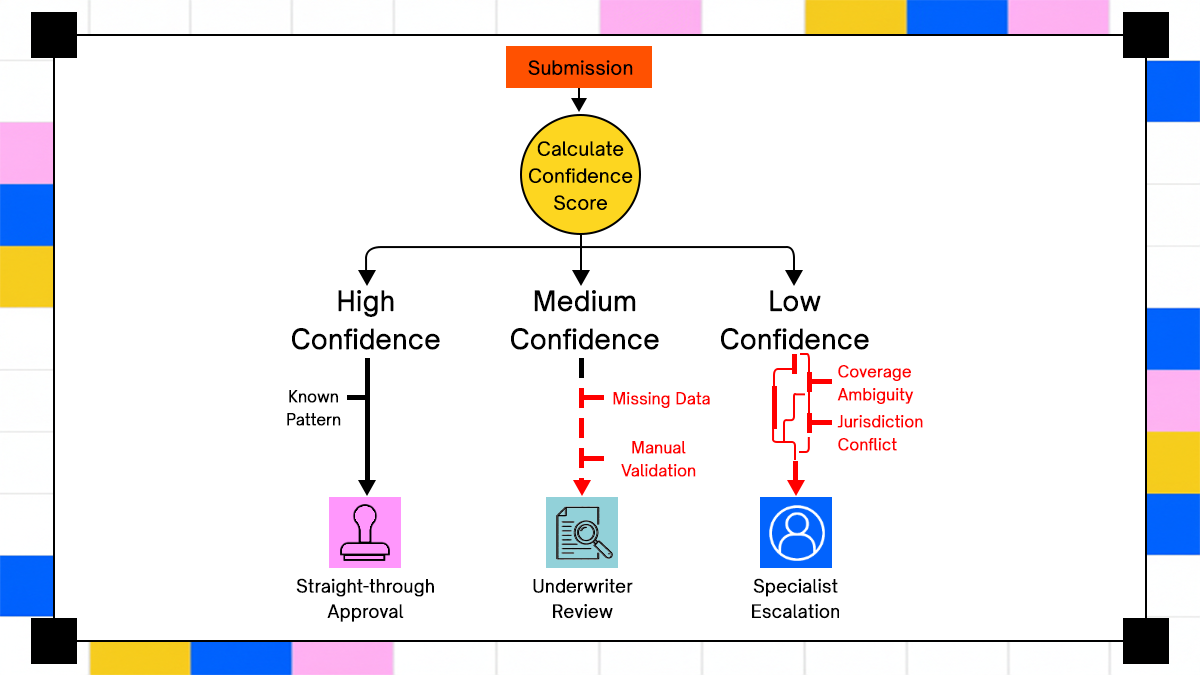
Fully autonomous underwriting remains rare in regulated environments because regulators in most U.S. states require that adverse underwriting decisions carry a documented rationale a human can review and defend. Carriers who push STP rates too high on complex books tend to discover pricing errors in their loss ratios before they find them in their model monitoring dashboards.
AI Underwriting Architectures Depend On Integration More Than Model Accuracy
A well-trained risk model is worth very little if it can't read from the carrier's policy admin system or write back to the broker portal. Most AI underwriting deployments that fail in production fail at the integration layer, not the model layer. What separates carriers that move from pilot to production is how well they've solved the plumbing before trying to optimize the prediction.
Core Insurance Platforms Create Integration Constraints For AI Deployment
Guidewire, Duck Creek, and most legacy policy administration systems were not designed with modern API-first architectures. Many carriers run on systems that process submissions in batch cycles, expose data through flat-file exports rather than real-time APIs, and maintain policy history in database structures requiring custom extraction logic.
Connecting a modern AI underwriting engine to these environments typically requires middleware bridging batch and real-time architectures, and each middleware layer introduces latency and new failure points. Carriers that prioritize API adapter development over rip-and-replace core system projects get 70% to 80% of the workflow benefit at a fraction of the disruption, which is why the orchestration layer often matters more to deployment success than the predictive model itself.
Retrieval Pipelines Reduce Hallucinated Decisions In Underwriting Workflows
Large language models used in underwriting document processing have a well-documented tendency to fill gaps with plausible-sounding but fabricated content, a failure mode that is particularly costly when the gap involves a policy exclusion, a coverage sublimit, or a jurisdiction-specific endorsement. Retrieval-augmented generation (RAG) addresses the problem by grounding model outputs in a controlled corpus of retrieved documents: in an underwriting context, the retrieval corpus includes the carrier's underwriting guidelines, product filing documents, state-specific endorsements, and prior policy history, and the model generates output based on retrieved passages rather than memory.
Without retrieval grounding, an LLM asked to assess coverage applicability may confidently cite a policy provision that doesn't exist in the carrier's filing, or omit an exclusion that materially changes the coverage interpretation. With it, any gap in the retrieval corpus becomes a visible missing citation rather than a silent fabrication, though retrieval pipelines require careful corpus maintenance: updated guidelines need re-indexing and deprecated policy language needs retiring before it gets cited in active submissions.
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
# Internal underwriting guidelines
guidelines = [
"Escalate commercial property applications above $10M coverage.",
"Reject policies with more than 3 fraud-related claims.",
"Require manual review for flood-zone commercial buildings."
]
# Create vector index
embeddings = OpenAIEmbeddings()
vector_store = FAISS.from_texts(
guidelines,
embedding=embeddings
)
retriever = vector_store.as_retriever()
# LLM retrieval chain
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(
temperature=0
),
retriever=retriever
)
# Underwriting question
query = (
"Should a flood-zone commercial property "
"requesting $15M coverage be escalated?"
)
response = qa_chain.run(query)
print("Underwriting Decision Guidance:")
print(response)
Agentic Underwriting Systems Introduce New Reliability Problems
Multi-agent underwriting systems, where separate agents handle document intake, risk enrichment, coverage mapping, and decision summarization, introduce error propagation that single-model systems don't face. A misclassified document in the intake agent produces a bad entity extraction, which feeds an incorrect risk signal to the scoring agent, which generates a summary that a human reviewer then has to untangle.
The specific failure modes include fabricated risk summaries, incorrect policy classifications, and missing escalation triggers where the orchestration logic fails to route a submission to a specialist. Bounded execution, defining strict limits on what each agent can act on without human confirmation, remains the most reliable control for high-severity decision paths.
What Insurance Teams Learn After Deploying AI Underwriting Systems At Scale
Pilots in underwriting AI tend to go well on clean datasets and fall apart on the first Monday morning of production, when the submission queue fills with handwritten ACORD forms, multi-page inspection reports with embedded tables, and loss runs spanning five policy periods from three different carriers.
Underwriters Shift From Data Entry To Exception Handling
When AI systems handle intake and pre-assessment, underwriters stop spending their days copying fields from PDFs into policy admin systems and start spending them reviewing flagged edge cases, evaluating submissions the model wasn't confident about, and managing exceptions to standard appetite.
The transition isn't frictionless: underwriters accustomed to seeing every submission from intake through decision often resist systems that pre-filter their queues. Carriers that invest in explainable output formatting, showing underwriters the specific features and retrieved policy provisions that drove the model's recommendation rather than a black-box score, report faster adoption and more consistent use.
Most Deployment Failures Start With Poor Data Hygiene
The gap between pilot and production is almost never a model quality problem; it's a data problem. Pilots run on curated datasets where someone has already cleaned the records, normalized the formats, and removed the duplicates. Production runs on ten years of policy history accumulated across three different admin systems, including migrations that left orphaned records and inconsistent field mappings.
Duplicate policy records, inconsistent loss history formats, missing training labels for edge-case submissions, and address standardization failures that prevent geospatial enrichment from matching to the right property are the failure modes that kill production deployments after successful pilots. The migration and cleanup work required before a production AI underwriting system can be trusted on a full submission book typically takes longer than building the model itself.
How Adopt AI Positions Agentic Systems Inside Insurance Operations
Most AI underwriting vendors compete on model accuracy or feature breadth. Adopt AI's positioning centers on the argument that the integration and orchestration layer is where insurance AI actually succeeds or fails, an argument that aligns closely with the operational problems production deployments consistently run into.
Adopt AI Focuses On Orchestration Across Existing Insurance Infrastructure
Rather than requiring carriers to replace their core platforms, Adopt AI operates as an agentic layer on top of existing systems, with agents working across internal tools, external portals, and legacy environments without rebuilding them.
The platform's open-source agent stack includes a Zero-Shot API Discovery capability that auto-generates tool cards for existing APIs without manual schema work, an Agent Orchestrator that selects the right agent or action based on user intent, and an Integration Bridge that connects to existing frameworks like LangGraph and LangChain.
The platform overview describes visual workflow orchestration that maps decision points and approval moments on a single canvas, scheduled data flows for syncing records across systems, and governance and security controls embedded at the workflow level, supporting the mixed-workflow environment that production underwriting deployments require: some submissions flowing straight-through, others routing to review queues, and high-severity cases escalating with full audit trails within the same orchestration layer.
Insurance AI Adoption Depends On Governance More Than Feature Breadth
The pattern that Adopt AI's research into AI insurance systems identifies as the differentiator between carriers that scale AI and carriers that stay in pilots is programmatic, cross-functional deployment treating data pipelines, tooling, and governance as enterprise infrastructure, rather than point solutions deployed function by function. Pilot programs fail to move into production most often because they were designed to demonstrate model capability rather than solve an integration or governance problem.
A model that scores well on a curated test set but lacks an audit trail, cannot explain its adverse decisions in plain language, and doesn't connect cleanly to the carrier's policy admin system is a demo, not a deployment. Adopt AI's platform positions governance and security as core platform capabilities rather than add-ons, which aligns with the regulatory direction the NAIC's 2023 bulletin and 2025 enforcement trajectory have established.
Enterprise Insurance Teams Need AI Systems That Operate Alongside Existing Workflows
The practical adoption constraint in most enterprise carrier environments isn't budget or executive sponsorship; it's underwriter acceptance. Underwriters who see AI as a replacement for their judgment resist it. Underwriters who see it as a system that pre-processes intake and flags cases for their attention, with a transparent explanation of what the system found and why it's flagging the case, adopt it faster and use it more consistently.
Adopt AI's positioning centers on outcome-driven interactions that adapt to user needs rather than requiring users to adapt to application workflows, directly addressing the acceptance barrier that derails many underwriting AI rollouts.
Conclusion
AI in insurance underwriting is shifting underwriting operations away from document-heavy intake queues and static rule engines toward systems that classify submissions, extract structured data, score risk, retrieve policy guidance, and route cases through controlled escalation paths. In this article, we examined how underwriting pipelines combine OCR, machine learning models, retrieval systems, orchestration logic, and human review controls to process insurance risk across fragmented carrier infrastructure. We also looked at the operational constraints behind production deployments, including legacy policy administration systems, data quality failures, regulatory oversight, explainability requirements, and the reliability risks introduced by agentic workflows.
The insurers moving beyond pilot deployments are not treating AI as a replacement for underwriting teams. They are treating it as workflow infrastructure that reduces intake overhead, improves submission routing, and gives underwriters more time to evaluate exceptions instead of manually collecting data from PDFs and broker emails all day. The hard part is no longer building a model. It is maintaining auditability, integrating with existing systems, controlling retrieval quality, and keeping underwriting decisions traceable when regulators, brokers, or claims disputes start asking uncomfortable questions.
FAQs
1. How Is AI Used In Insurance Underwriting Workflows?
AI underwriting systems process submissions, classify documents, extract applicant data, and generate preliminary risk scores before cases reach human reviewers. Insurers also use AI to route low-risk policies through straight-through processing and escalate exceptions for manual review.
2. Can AI Replace Human Insurance Underwriters?
AI can reduce repetitive intake and screening work, but commercial underwriting still depends heavily on human judgment for exceptions, policy interpretation, and regulatory review. Most insurers use AI as a decision-support layer rather than a replacement system.
3. What Data Sources Are Used In AI Underwriting Systems?
Underwriting models use policy history, claims records, financial data, credit scores, inspection reports, medical records, telematics, geospatial data, and third-party risk databases. Many systems also process unstructured broker submissions and scanned documents.
4. How Do Insurers Audit AI Underwriting Decisions?
Insurers maintain audit trails containing model versions, input data, decision logs, confidence scores, and escalation records. Explainability tooling and retrieval systems help compliance teams trace why a policy received a specific underwriting outcome.

.svg)
.svg)


Take three minutes to find out which side of that line you are on.
Browse Similar Articles



Find Your Agentic AI Readiness Score
Every enterprise thinks they are building toward Agentic AI. But only few actually are.
Take three minutes to find out which side of that line you are on.












