Compare 6 enterprise AI agent systems based on execution guarantees, reliability, and performance, not model quality. Choose the right solution for pr




TL;DR
- Most AI initiatives die because they prioritize model "smarts" over boring system reliability. Demos look great with high-quality text, but production systems fail when they can't handle a simple network timeout or a partial API success.
- An agent without a durable state is just a fancy script that forgets where it left off. Correctness over time requires a system that records every intermediate step, ensuring it resumes from a failure point rather than blindly double-charging a customer.
- In distributed systems, retries are inevitable, making idempotency a non-negotiable requirement. If your agent doesn't check if an action, like a payment or a ledger update, was already completed, you are building a system that actively corrupts your data.
- Frameworks like LangChain or AutoGen excel at flexible thinking but often crumble under strict execution requirements. For mission-critical tasks, you need orchestration-first architectures like Adopt AI or Temporal that treat AI as a component within a rigid, stateful machine.
- Standard logs are useless when debugging non-deterministic agent loops across multiple systems. You need structured, step-level traces that map the exact transition from a model's decision to a system's side effect to identify where the logic actually drifted.
- The fastest path to development is rarely the safest path to deployment. High-reliability agents require upfront engineering effort to define clear boundaries and compensation logic, shifting the focus from "prompt engineering" to "distributed systems design."
Enterprise AI agents are entering production environments faster than the surrounding infrastructure can support them. The gap shows up in failure reports, not in demos. Gartner states that over 30 percent of generative AI initiatives will not reach production due to unclear value, risk, and operational complexity. That statistic often gets read as a business problem, but the underlying cause sits in system design.
Statista data shows enterprise AI spending continuing to rise across sectors, yet reliability concerns rank alongside cost as a primary blocker. Engineers are not debating model accuracy at that stage. They are debugging retries that double-charge customers, workflows that stop halfway, and systems that cannot explain what they just did.
A typical internal postmortem does not say “the model hallucinated.” It says a retry loop re-executed a payment step after a timeout, or a workflow lost track of progress after a partial API failure. These are distributed systems problems. The presence of a language model does not remove them, it adds another source of non-determinism.
This article treats enterprise AI agents as execution systems first. You will see how different architectures behave when exposed to real conditions such as retries, partial success, and long-running workflows. The comparison stays grounded in failure behavior, because that is where systems reveal their design limits.
What are Enterprise AI Agents
Enterprise AI agents are software systems designed to execute and manage workflows across multiple tools and data sources within an organization. They go beyond generating responses by taking actions, following defined processes, and maintaining accuracy over time. In an enterprise context, they are valued for their ability to handle complex, multi-step operations while ensuring consistency, reliability, and alignment with business rules.
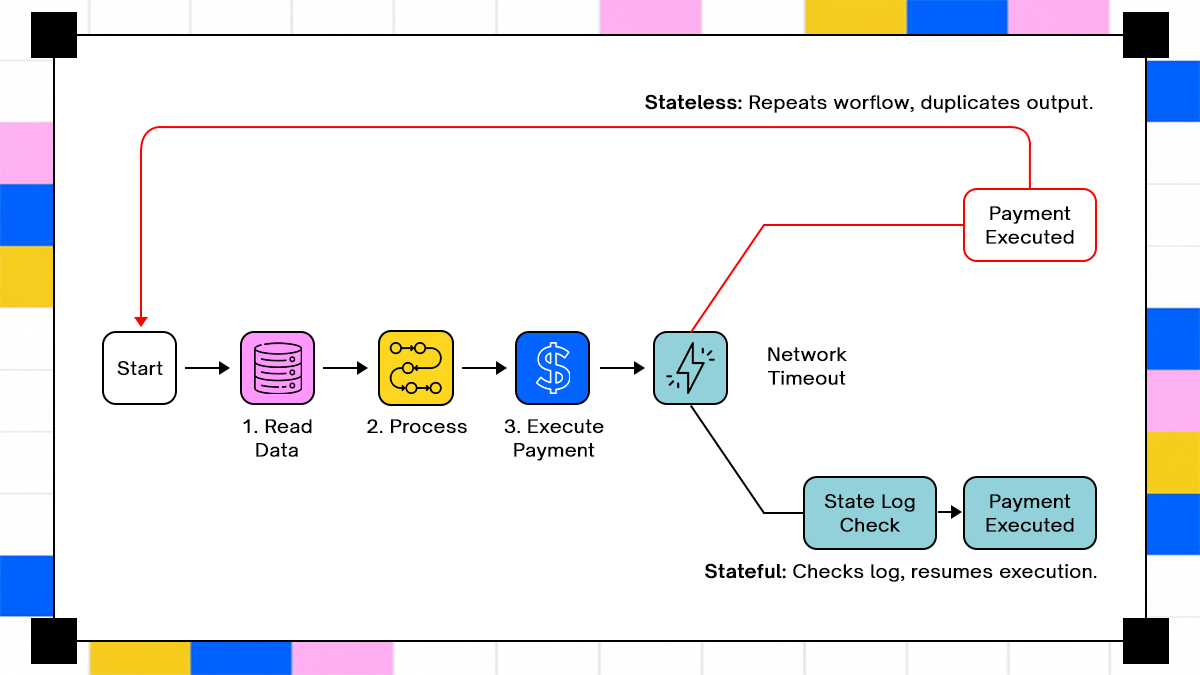
Where Do Enterprise AI Agents Sit
An enterprise AI agent sits between intent and execution. It receives a goal such as “reconcile transactions for yesterday,” decomposes it into steps, and executes those steps across systems like payment gateways, internal ledgers, and accounting platforms. Each step introduces a state, and that state must persist beyond a single request.
The boundary becomes clearer when you map the lifecycle. The agent must store intermediate results, track which steps have completed, and decide how to proceed when something fails. A stateless system cannot do this reliably because it has no memory of what has already happened.
Consider a reconciliation workflow:
- Fetch transactions from gateway
- Match against internal ledger
- Apply adjustments in accounting system
If step three fails after step two completes, the system must resume from step three without repeating earlier steps. That requirement alone forces the agent to behave like a stateful workflow engine rather than a prompt-response system.
How Enterprise AI Agents Are Different from Other Tools
Chatbots operate on single-turn or short multi-turn interactions. They do not manage long-running execution or external state. RPA tools execute predefined steps with deterministic logic. They fail when inputs vary or when decision-making becomes complex.
Function calling frameworks extend models with API access, but they still operate within a request-response lifecycle. They do not persist in the execution context unless developers build that layer separately.
Enterprise AI agents combine three capabilities:
- Decision-making using models
- Execution across external systems
- State persistence across time
Missing any one of these reduces the system to a prototype. Many “agent” implementations today are function-calling wrappers with no durable state. They work in demos because execution is short-lived and controlled.
How Enterprise AI Agents Work in Practice
Correctness over time defines success. A system that produces the right answer once but fails under retries is not usable in production.
Execution spans minutes, hours, or even days. During that time, APIs may fail, schemas may change, and external systems may behave unpredictably. The agent must maintain a consistent view of progress despite these conditions.
The requirement shifts the design focus. Instead of asking “did the model produce the right output,” teams must ask “can the system recover from failure without corrupting data.” That question leads directly to concepts such as idempotency, durable state, and replay-safe execution.
How We Selected These Enterprise AI Agent Systems
Selection criteria matter because most agent comparisons bias toward model capability or ecosystem size. That approach hides the execution limits that show up in production.
1. Adoption Across Enterprise Teams
The systems in this list appear repeatedly in real deployment discussions across platform teams and DevOps environments. That includes internal tooling, integration pipelines, and automation layers tied to business-critical systems.
Adoption alone is not a quality signal, but it exposes systems to real traffic patterns. A framework used only in demos never encounters retry storms, rate limits, or schema drift. Systems used in production accumulate those failure patterns quickly.
A useful filter is where engineers spend time debugging. If a system shows up in incident reviews, it has crossed from experimentation into operational reality.
2. Coverage Across Different Agent Architectures
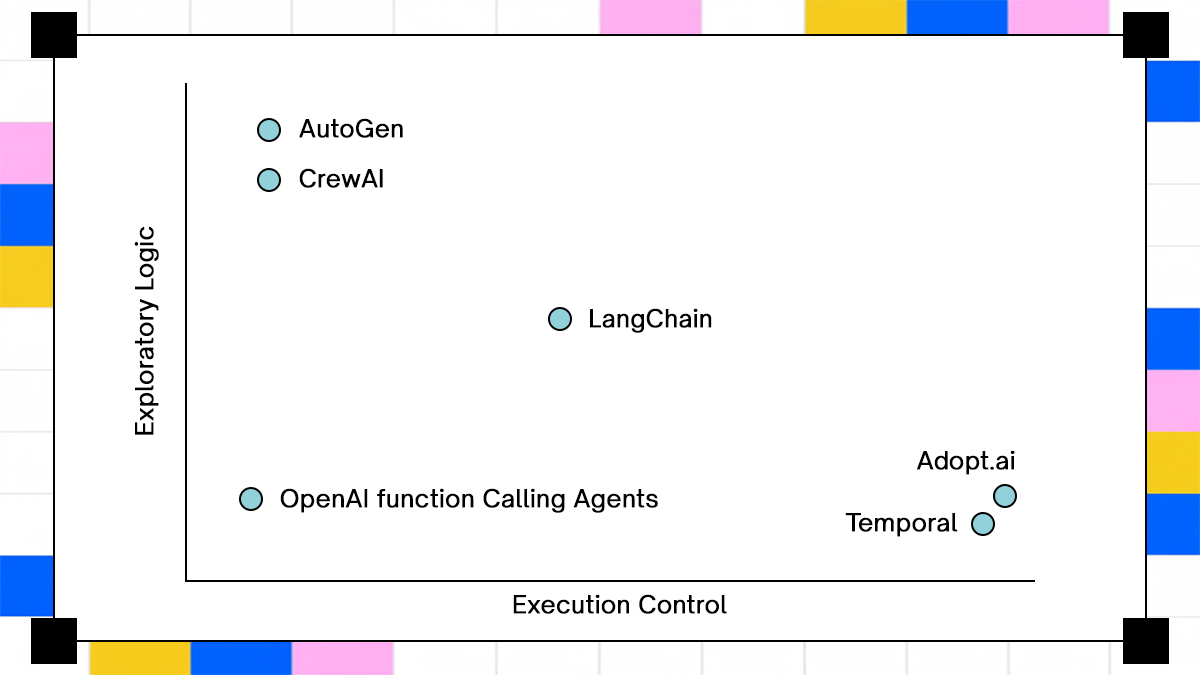
The list covers three distinct approaches:
- Orchestration-first systems where execution state is primary
- Reasoning-first frameworks where decision-making drives flow
- Hybrid systems combining workflow engines with model-based decisions
Comparing only similar systems hides trade-offs. A reasoning-first framework may look flexible until it encounters a multi-step workflow with strict consistency requirements.
An orchestration-first system may feel rigid during development but behaves predictably under failure. The comparison only becomes meaningful when both are evaluated under the same conditions.
3. Real-World Failure Patterns and Production Evidence
The evaluation draws from recurring failure patterns observed in engineering teams:
- Retry loops causing duplicate operations
- Workflows failing mid-execution without recovery
- Inconsistent state across systems after partial success
- Lack of traceability when debugging production issues
These patterns appear across industries. Financial systems expose them through reconciliation errors. E-commerce systems surface them through duplicate orders. Internal tooling reveals them through inconsistent data pipelines.
The goal is not to rank systems by features. It is to map where each system’s design assumptions stop holding under these conditions.
Evaluation Criteria: What Actually Gets Tested
Most evaluations stop at “does it work.” Production systems require a different question: “does it continue working when conditions degrade.”
1. State persistence
State persistence determines whether a system can survive interruption. Each step in a workflow must record its outcome in a durable store.
Without persistence, a system cannot distinguish between completed and pending steps. It either repeats work or stops entirely.
A simple example shows the difference:
- Stateless execution: restart entire workflow after failure
- Stateful execution: resume from last completed step
The second approach reduces load and prevents duplicate side effects. It also enables long-running workflows where execution spans multiple sessions.
State persistence also supports auditability. Teams can inspect what happened at each step, not just the final outcome.
2. Idempotency
Idempotency ensures that repeating an operation does not change the result. The property is essential in systems that retry operations.
Consider a payment step. If a retry occurs, the system must recognize that the payment has already been applied. Without idempotency, retries create duplicate charges.
Implementing idempotency requires:
- Unique identifiers for each operation
- Storage of execution results
- Checks before performing actions
The pattern often looks like this:
async function processPayment(id, action, store) {
const existing = await store.get(id);
if (existing) {
return existing;
}
const result = await action();
await store.save(id, result);
return result;
}
Though the logic appears simple, it becomes complex when workflows span multiple systems with different guarantees.
3. Error handling
Errors in distributed systems are not binary. A workflow may partially succeed before failing.
Error handling must distinguish between:
- Retryable failures, such as network timeouts
- Non-retryable failures, such as validation errors
- Partial success, where some steps completed
A system that treats all failures the same either retries too aggressively or stops prematurely.
Effective error handling requires:
- Classification of failure types
- Step-level recovery strategies
- Compensation logic for irreversible actions
Compensation becomes necessary when an action cannot be undone directly. For example, reversing a payment requires a new transaction rather than deleting the original.
4. Integration behavior
External systems introduce variability. APIs change, rate limits fluctuate, and data formats evolve.
An enterprise agent must account for:
- Schema changes that break parsing logic
- Rate limits that delay execution
- Partial responses that require validation
Ignoring these factors leads to brittle workflows. Systems that treat integrations as static dependencies fail when real-world conditions change.
Integration-aware systems include validation layers and fallback strategies. They detect anomalies early rather than propagating errors downstream.
5. Observability
Observability determines whether teams can debug failures. Logs alone are insufficient when workflows span multiple steps and systems.
A useful system provides:
- Step-level execution traces
- State transitions over time
- Correlation between actions and outcomes
Without structured observability, debugging becomes guesswork. Teams rely on log scanning instead of understanding execution flow. Observability also supports incident response. When a workflow fails, operators need to identify the exact step and reason without reconstructing the entire process manually.
Top 6 Enterprise AI Agents
The following systems represent different approaches to building enterprise AI agents. Each one reflects a set of design decisions that influence how it behaves under production conditions. The comparison focuses on execution behavior rather than feature lists. Each section examines where the system performs well, where it starts to degrade, and why those limits appear.
1. Adopt AI
Adopt AI treats workflows as persistent processes rather than transient executions. That design choice changes how the system behaves under failure.
What it does
Adopt AI runs agents against live application interfaces and APIs while maintaining execution state across steps. Documentation describes workflows as long-running processes with built-in tracking and recovery.
The system focuses on execution continuity. Each step writes its outcome, allowing the workflow to resume without recomputing prior steps.
Where it works well
- Multi-system workflows benefit from explicit state tracking. When operations span ERP, CRM, and billing systems, the agent maintains a consistent view of progress.
- Regulated environments require audit trails. Adopt AI records execution history, enabling teams to trace actions and decisions.
- Teams replacing extraction-based automation tools see improvements in reliability. Instead of processing documents in isolation, the system integrates them into workflows with defined states.
Where it gets stressed
Ambiguity in upstream inputs affects workflow branching. If classification steps are incorrect, downstream execution follows the wrong path.
Rapid changes in external systems introduce edge cases. When APIs evolve mid-execution, the agent must adapt without breaking state consistency.
What breaks and why
Incorrect upstream classification leads to incorrect execution paths. The system relies on accurate inputs to determine workflow branches.
Human-in-the-loop steps introduce concurrency challenges. When multiple workflows require manual intervention, coordination becomes complex.
Execution behavior under failure
Adopt AI records step-level progress and resumes execution from the last completed step. Official descriptions focus on continuity rather than replay, which aligns with durable execution patterns.
Retries operate at the step level instead of restarting entire workflows. It reduces duplicate side effects and improves recovery speed.
Verdict
Strong fit for teams prioritizing execution guarantees and auditability across long-running workflows.
2. LangChain Agents
LangChain provides flexibility for building agent systems, but leaves execution guarantees to the developer.
What it does
It enables chaining of model calls and tool integrations. Developers define how agents interact with external systems.
The framework focuses on composition. It allows rapid assembly of workflows using predefined components.
Where it works well
- Prototyping benefits from its flexibility. Teams can quickly connect models to APIs and test workflows.
- Custom systems can be built on top of LangChain. Engineers extend it with their own state management and retry logic.
Where it gets stressed
Long-running workflows expose gaps in persistence. Without built-in state tracking, the system struggles to resume execution.
Multi-step chains become fragile under failure. Each step depends on prior context, which may not persist reliably.
What breaks and why
Implicit state handling leads to inconsistent retries. The system cannot always determine which steps have been completed.
Error propagation across chains becomes difficult to trace. Failures may surface far from their origin.
Execution behavior under failure
Retries often restart execution from the beginning. Recovery depends on custom logic implemented by the team.
State reconstruction requires additional infrastructure. Without it, workflows remain brittle.
Verdict
Effective for rapid development, requires significant engineering effort to achieve production reliability.
3. CrewAI
CrewAI focuses on multi-agent collaboration rather than deterministic execution.
What it does
Agents operate with defined roles and share context to achieve a goal. Tasks are distributed across agents.
The system emphasizes coordination and communication between agents.
Where it works well
- Collaborative workflows benefit from this model. Tasks such as analysis or planning can be distributed across agents.
- Scenarios with flexible outcomes do not require strict consistency.
Where it gets stressed
Transactional workflows require deterministic execution. CrewAI does not enforce strict sequencing or state guarantees.
Systems with side effects need precise control. Coordination alone is not sufficient.
What breaks and why
Shared context drifts over time. Agents may operate on inconsistent information.
Coordination lacks strong guarantees. Without a centralized state, execution becomes unpredictable.
Execution behavior under failure
Recovery often requires restarting workflows. Partial execution tracking is limited.
Failures propagate through agent interactions rather than structured state transitions.
Verdict
Suitable for collaborative reasoning tasks, less appropriate for systems requiring strict execution guarantees.
4. AutoGen
AutoGen extends the multi-agent idea into conversational loops where agents iteratively refine outputs. That approach works when the task benefits from exploration, but it exposes limits once execution must remain consistent across systems.
What it does
AutoGen allows multiple agents to communicate, delegate tasks, and call tools while iterating toward a result. Each agent operates with a role and contributes to a shared outcome.
The system treats problem solving as a conversation. Agents propose actions, critique outputs, and refine decisions across turns.
Where it works well
- Research workflows benefit from iterative refinement. Tasks such as analysis, summarization, or planning do not require strict sequencing or side-effect control.
- Exploratory problem solving fits well. Agents can attempt multiple approaches without strict constraints on execution order.
Where it gets stressed
External integrations introduce constraints that conversational reasoning cannot resolve. APIs require strict input formats, sequencing, and validation.
Workflows with dependencies between steps require deterministic execution. Iteration alone cannot guarantee correctness.
What breaks and why
The system assumes reasoning can compensate for execution uncertainty. Without structured state, agents lose track of what has already been executed.
Context drift occurs as conversations grow. Agents may operate on outdated or inconsistent information.
Execution behavior under failure
Failures propagate through conversation rather than structured recovery. Replaying a workflow requires reconstructing the conversation, which is not deterministic.
Partial execution is difficult to isolate. The system lacks step-level checkpoints that enable resumability.
Verdict
Effective for iterative reasoning tasks, not suited for workflows where execution must remain consistent across systems.
5. Temporal + LLM Integration
Temporal changes the problem space by treating workflows as durable processes with explicit state transitions. Adding LLMs introduces decision-making without replacing execution control.
What it does
Temporal provides a workflow engine that persists state, tracks execution history, and controls retries. LLMs are integrated as decision points within these workflows.
The system separates concerns. Temporal handles execution, while the model handles decisions.
Where it works well
- High-reliability systems benefit from deterministic execution. Workflows that involve payments, provisioning, or compliance processes require strong guarantees.
- Retry and compensation logic are first-class features. Teams can define how failures are handled at each step.
Where it gets stressed
Workflow design requires upfront effort. Engineers must define each step and transition explicitly.
Iteration slows when workflows change frequently. Updates require modifying workflow definitions and redeploying.
What breaks and why
Complexity increases as workflows grow. Managing large workflows requires careful structuring and versioning.
Tight coupling between workflow logic and infrastructure introduces maintenance overhead.
Execution behavior under failure
Temporal resumes workflows from the last recorded state. Retries follow defined policies, preventing duplicate execution.
Each step is recorded, enabling traceability and debugging. The system guarantees that completed steps are not re-executed unless explicitly configured.
import { proxyActivities } from '@temporalio/workflow';
const { sendInvoice } = proxyActivities({
startToCloseTimeout: '1 minute',
});
export async function invoiceWorkflow(id: string) {
await sendInvoice(id);
}
Verdict
Best suited for teams that need strict execution guarantees and are willing to manage workflow definitions explicitly.
6. OpenAI Function Calling Agents
Function calling provides structured interaction between models and APIs, but it does not provide execution control beyond a single request.
What it does
Models generate structured outputs that map to predefined functions. The system executes those functions and returns results.
The approach keeps interactions predictable within a single request lifecycle.
Where it works well
- Simple workflows benefit from direct function invocation. Tasks that require one or two steps can be handled without additional orchestration.
- Controlled environments with limited execution depth fit well.
Where it gets stressed
Multi-step workflows require coordination between steps. Without a persistent state, the system cannot track progress reliably.
External systems introduce variability. Retries must be handled outside the function-calling mechanism.
What breaks and why
Retries can repeat actions because the system lacks awareness of prior execution. Side effects accumulate without control.
No orchestration layer exists to manage dependencies between steps. Each function call operates in isolation.
Execution behavior under failure
Recovery depends entirely on external logic. Developers must implement state tracking and retry control separately.
Resumability is not supported natively. Workflows must be reconstructed manually after failure.
Verdict
Suitable for bounded tasks, not appropriate for long-running workflows involving multiple systems.
Comparison: Execution Guarantees vs Flexibility
The systems above fall into two categories. Some prioritize execution guarantees, while others prioritize flexibility and rapid iteration.
Dimensions
- State management determines whether workflows can resume without duplication.
- Retry control defines how systems behave under failure.
- Observability affects debugging and incident response.
- Workflow duration reflects how long systems can operate reliably.
Narrative explanation
Orchestration-first systems such as Adopt AI and Temporal enforce execution guarantees. They treat workflows as state machines with explicit transitions. Reason-first systems such as LangChain, CrewAI, and AutoGen prioritize flexibility. They rely on model-driven decisions and require additional layers to handle execution complexity.
Function calling sits at the lowest level. It provides structured interaction but no orchestration. The trade-off is clear. Flexibility enables rapid development, but execution guarantees determine whether the system survives production.
Real-World Scenario: Multi-System Financial Reconciliation
A reconciliation workflow exposes execution issues quickly because it involves multiple systems and strict correctness requirements.
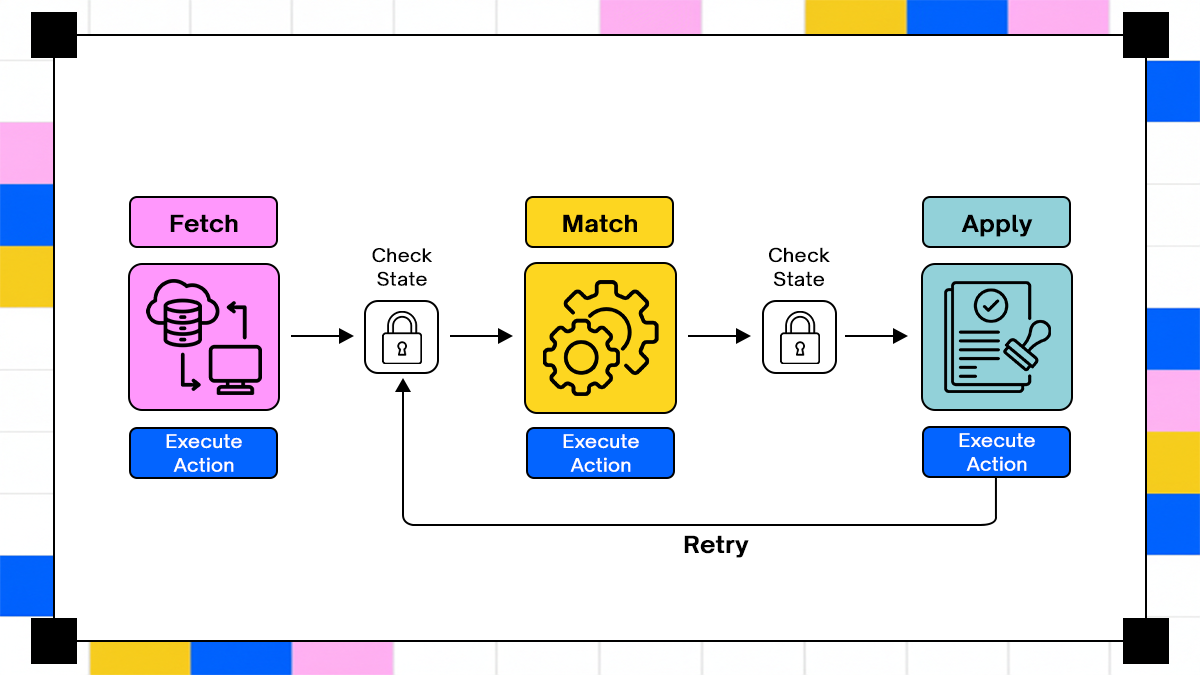
Workflow description
The agent retrieves transactions from a payment gateway, matches them against an internal ledger, and applies adjustments in an accounting system. Each step depends on the previous one. Errors at any stage can create inconsistencies.
Failure contrast
A naive system retries the entire workflow after failure. A stateful system resumes from the failed step. The difference becomes visible under load. Replaying the entire workflow increases the risk of duplicate actions.
Side-effect risks
Duplicate adjustments occur when retries reapply completed steps. Financial systems surface these errors immediately. Even a single duplicate operation can require manual correction and audit review.
State tracking model
A state-aware system records progress at each step.
{
"workflow_id": "reconcile_123",
"steps": [
{ "id": "fetch_transactions", "status": "done" },
{ "id": "match_records", "status": "done" },
{ "id": "apply_adjustments", "status": "pending" }
]
}
The structure allows the system to resume execution without repeating completed steps.
Code example
async function executeStep(stepId, action, store) {
const record = await store.get(stepId);
if (record?.status === 'done') {
return record.result;
}
const result = await action();
await store.save(stepId, {
status: 'done',
result
});
return result;
}
The pattern ensures idempotency and supports safe retries.
Conclusion
Enterprise AI agents are usually evaluated based on model performance, but real-world failures come from how the system executes workflows. The breakdown happens between steps, not inside the model. Retries, partial execution, and inconsistent external systems expose weaknesses in how workflows are designed and executed.
The comparison across Adopt AI, LangChain, CrewAI, AutoGen, Temporal, and function calling systems shows a clear pattern. Systems that treat execution as a first-class concern maintain correctness under stress. Systems that rely on reasoning without structured state struggle once workflows extend beyond simple tasks. The difference appears when something fails, not when everything works. Adopt AI and Temporal enforce stateful execution, which allows workflows to resume safely and prevents duplicate side effects. LangChain, CrewAI, and AutoGen provide flexibility for building agents, but require additional layers to achieve the same guarantees. Function calling remains useful for bounded interactions, but does not address orchestration.
Enterprise AI agents behave like distributed systems with probabilistic decision layers. Designing them requires the same discipline as any system handling financial transactions, provisioning workflows, or compliance processes. Without state persistence, idempotency, and structured observability, even a well-performing model cannot prevent data inconsistencies.
Frequently Asked Questions
1. When do enterprise AI agents require durable state instead of stateless execution?
Workflows involving multiple dependent steps require durable state. Stateless execution works only for isolated tasks.
2. How should retries be designed to avoid duplicate side effects?
Retries must use idempotent operations and track execution state. Each step should run safely multiple times.
3. When should teams choose orchestration-first systems over reasoning-first frameworks?
Choose orchestration-first systems for workflows involving external systems and long execution times.
4. How do enterprise constraints like compliance and auditability affect agent design?
Audit requirements require traceable execution and deterministic recovery. Systems must record every step and decision.

.svg)
.svg)


Take three minutes to find out which side of that line you are on.
Browse Similar Articles



Find Your Agentic AI Readiness Score
Every enterprise thinks they are building toward Agentic AI. But only few actually are.
Take three minutes to find out which side of that line you are on.












