Learn what hyperautomation is and how AI transforms business automation. Explore benefits, use cases, and strategies for 2026.




TLDR;
- A "200 OK" from an API doesn't guarantee system integrity if the surrounding workflow lacks context. Without state, a simple retry of a successful step creates duplicate payments or fractured CRM records that stay hidden for hours.
- Standard integration tools treat every run as a clean slate, which is a lethal assumption for long-running processes. When execution spans minutes or hours, the platform must act as a persistent ledger of progress, not just a blind pipe for data.
- Blindly replaying a failed sequence is the fastest way to corrupt downstream data. True hyperautomation requires "checkpointing" where the system resumes from the exact point of failure, ensuring side effects are never triggered twice.
- While developers aim for idempotent APIs, the reality is a mess of legacy systems and inconsistent vendors. The workflow engine must bridge this gap by storing unique execution IDs that force consistency even when the destination API is fragile.
- Linear workflows break the moment an API schema drifts or a rate limit hits. Resilient systems use execution graphs that pause, branch, and adapt at runtime, treating failures as routine state changes rather than terminal errors.
- Moving beyond iPaaS means giving every workflow a permanent identity that survives process restarts. Success is no longer about "trigger and forget" but about maintaining a durable, stateful record that converges on the correct outcome regardless of network noise.
A workflow can pass API validation and still corrupt production data when retries replay side effects without context. The failure shows up hours later, not at execution time, which makes it harder to trace and even harder to fix.
Industry data reflects how common automation complexity has become. Gartner projected that organizations adopting hyperautomation would lower operational costs by up to 30 percent by 2024, driven by increasing automation depth across systems. A parallel trend appears in integration growth. Statista reports steady expansion in enterprise application counts and integration demand, which directly increases workflow complexity and failure surface.
Production discussions tell the same story in plain terms. Threads on Reddit communities such as r/devops regularly describe duplicate payments, partial CRM writes, and workflows that “succeed” while leaving systems inconsistent. The pattern is not tied to a specific tool. It shows up whenever execution assumes that each run starts clean and ends clean.

The underlying issue is not API connectivity but it is how execution is modeled. Short-lived workflows treat time as irrelevant. Long-running workflows depend on time, retries, and intermediate state. This article examines that shift in detail. It starts with where iPaaS works as expected, then traces where it fails under real system behavior. It then moves into the execution model changes required when workflows become stateful and long-running.
What iPaaS Actually Does Well, and Where It Starts Breaking
iPaaS platforms were built to connect systems through event-driven triggers and predefined integrations. That model works well under a narrow set of conditions where execution is short, predictable, and completes within a single request window.
Under those conditions, a workflow behaves like a transaction pipeline. An event arrives, a sequence of API calls executes, and the system returns success or failure immediately. There is no need to persist in the intermediate state because the entire workflow completes before external conditions change.
A typical example looks simple on paper: a webhook triggers when a user signs up, the system creates a CRM record, provides access in another service, and sends a confirmation email. Each step depends only on the input event and immediate API responses. No step needs to remember what happened five minutes earlier.
This model starts to break as soon as execution spans time or depends on external systems with inconsistent guarantees. Consider a billing workflow that processes thousands of invoices. External APIs enforce rate limits, which means execution stretches across hours. Some calls succeed, others fail, and retries must be scheduled later. A platform that expects a single execution window cannot represent that timeline accurately.
The failure mode is subtle; The platform reports a failed workflow, but it does not retain a structured record of which steps succeeded. Engineers then retry the workflow, which replays already completed steps. Duplicate invoices appear, or downstream systems reject requests due to conflicting state.
Another issue appears when APIs change behavior. A connector built against a fixed schema fails when a vendor introduces a new required field. The workflow breaks at runtime, not during design, and the platform has no built-in mechanism to adapt. iPaaS does not fail because it cannot call APIs. It fails because it assumes execution is short-lived and fully observable within a single run. Once that assumption breaks, correctness depends on factors the platform does not track.
The Hidden Assumption: Stateless Execution
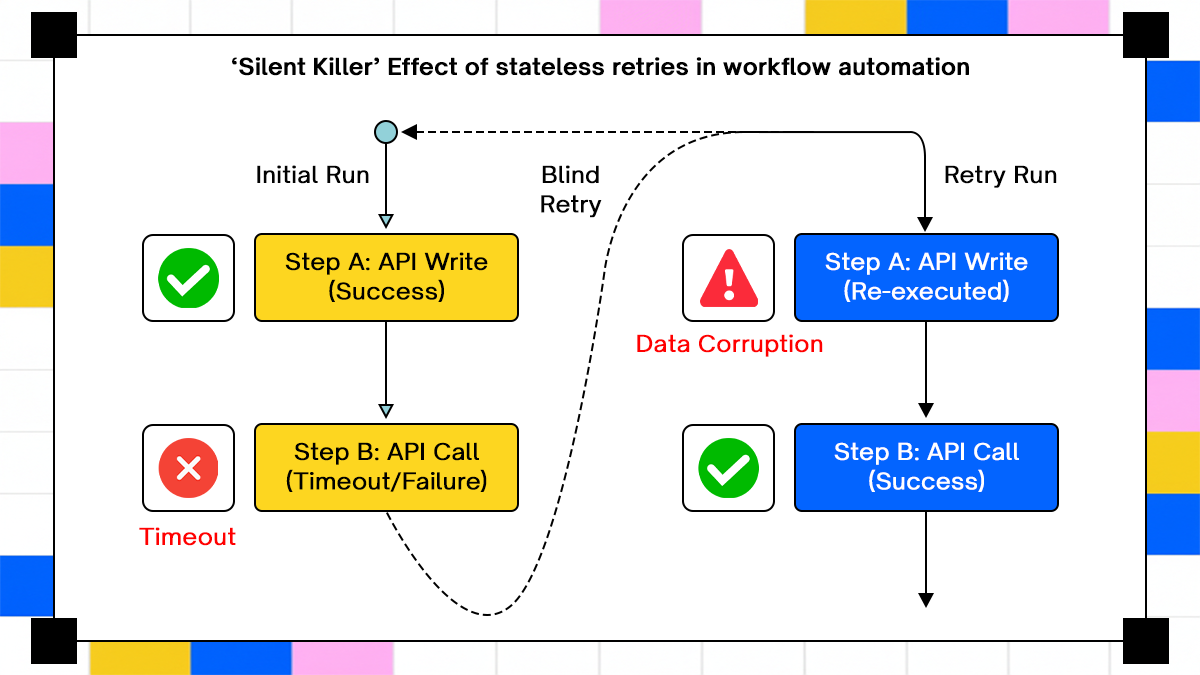
To understand why these failures persist, it helps to look at the execution model itself rather than individual features. Most integration platforms treat each workflow run as independent. Execution begins with an input event, proceeds through a sequence of steps, and ends with a success or failure state. After completion, the system stores logs but not a structured representation of the execution state.
That design choice creates a blind spot around retries. When a workflow fails midway, a retry starts from the beginning without awareness of prior progress. The system cannot distinguish between steps that have already succeeded and steps that still need execution. Every retry becomes a full replay.
In distributed systems, replay without context is risky. API calls often produce side effects that cannot be safely repeated. Creating a record, charging a payment, or sending a notification changes external state in ways that are not automatically reversible.
Idempotency is often suggested as a solution, but implementing it across multiple systems is not trivial. Each API must support idempotent operations, and the workflow must track identifiers that allow safe retries. Without a persistent state, there is no reliable place to store or enforce those guarantees.
Another issue appears with delayed retries. Rate-limited APIs require backoff strategies that span minutes or hours. A stateless execution model cannot pause and resume reliably because it does not maintain execution context outside the original run. This limitation shows up in production as either dropped retries or manual intervention. Engineers end up writing external scripts or storing state in databases to compensate for what the platform does not track.
The iPaaS layer handles API calls, while custom code handles correctness. That division increases complexity and creates failure paths that are difficult to test. Stateful workflows change that model by treating execution as something that persists over time, not something that exists only during a single run. The next section moves into where this becomes unavoidable and how real systems expose these gaps.
Where Real Systems Break: Long-Running and Stateful Workflows
Short-lived workflows assume a clean start and a clean finish. Real systems rarely behave that way once external dependencies and time enter the picture. Take a payment reconciliation pipeline between a payment gateway and an internal ledger. The gateway processes transactions in near real time, while the ledger updates in batches every fifteen minutes due to database constraints. A workflow triggers on each transaction, attempts to write into the ledger, and retries when the ledger API rejects requests due to load.
At minute one, half the transactions succeed. At minute five, retries begin. At minute fifteen, the ledger batch completes and accepts new writes. The workflow now needs to know which transactions were already written, which failed due to transient errors, and which failed due to validation issues.
A stateless system cannot answer that question. It only knows that previous runs failed. When retries execute, they replay all steps. Some transactions are inserted twice, others are rejected due to duplicate keys, and a few remain missing because earlier failures were never retried with correct parameters.
Another example shows up in SaaS provisioning flows. A new enterprise customer signs up, which triggers a workflow that provisions accounts across identity, billing, analytics, and support systems. Each system has different latency characteristics. Identity completes immediately, billing requires fraud checks, analytics queues background jobs, and support tooling depends on asynchronous API availability.
Provisioning stretches across hours. Failures appear at different stages, often after earlier steps have already committed changes. If the workflow fails after billing but before analytics, a retry must resume from analytics without re-running billing. Without a persistent state, the system cannot enforce that boundary.
Engineers often try to patch this with flags stored in external databases. Each workflow step writes a status record, and retries consult that record before executing. That approach works until concurrency increases. Multiple retries race, state becomes inconsistent, and manual reconciliation becomes the only safe recovery path.
Long-running workflows force a different requirement. Execution must persist beyond a single process lifetime. The system must remember what has already happened and make decisions based on that memory. Without that, correctness depends on luck and manual cleanup.
Failure Modes That iPaaS Does Not Handle Well
These issues are not theoretical; They show up as repeat incidents across integration-heavy systems. Each one ties back to missing execution state and lack of control over retries.
1. Partial Writes Across Systems
Consider an order synchronization workflow between an e-commerce platform and an ERP system. The workflow creates an order in the ERP, then updates inventory, then triggers shipping.
The ERP call succeeds, inventory update fails due to a temporary lock, and shipping never triggers. The workflow reports failure. A retry runs the same sequence again. The ERP now contains two orders for the same purchase, inventory updates correctly, and shipping triggers twice.
The root problem is not failure. The system lacked awareness that the ERP write already succeeded. Without that knowledge, retries produce duplicate side effects. Production systems often detect this hours later when reconciliation jobs flag mismatches. By then, downstream systems have already processed incorrect data.
2. Non-Idempotent Retries
Retries are unavoidable in distributed systems. Networks fail, APIs throttle requests, and transient errors occur even under stable conditions. A workflow that retries blindly assumes that repeating a request produces the same outcome. That assumption only holds when APIs are idempotent and when the workflow enforces idempotency keys consistently.
In practice, many APIs do not guarantee idempotency across all endpoints. Even when they do, the workflow must attach identifiers that allow the API to recognize repeated requests.
A common failure appears in subscription billing. A retry after a timeout may create a second charge if the payment provider processes the first request but the response is lost. Without idempotency keys tied to workflow state, the system cannot distinguish between a failed request and a delayed response. Engineers often discover this through customer complaints rather than monitoring alerts. The system reports success on retry, while the customer sees two charges.
3. API Schema Drift
APIs evolve. Fields become required, validation rules change, and response formats shift over time. Connector-based systems encode API structure at design time. When the API changes, the connector becomes outdated.
A workflow that worked yesterday fails today because a new required field is missing. The failure appears during execution, not during deployment. In high-volume systems, this leads to cascading failures. Thousands of workflow executions fail within minutes, each requiring retries or manual fixes.
Some teams attempt to version connectors or monitor API changes. That approach reduces impact but does not eliminate the issue. The system still depends on static definitions that lag behind real API behavior.
4. Rate Limits and Backoff Behavior
External APIs enforce limits that restrict how frequently requests can be made. Workflows must respect those limits and retry later when capacity becomes available. A short-lived execution model struggles with delayed retries. If a workflow fails due to rate limiting, it either retries immediately and fails again or schedules a retry without retaining full execution context.
In batch processing scenarios, this creates uneven progress. Some records complete, others remain pending, and retries accumulate over time.
A logistics system integrating with a shipping provider often encounters this issue. Bulk shipment creation hits rate limits, retries spread across minutes or hours, and partial completion leads to inconsistent shipment states. Without a persistent state, the system cannot track which shipments were successfully created and which remain pending. Engineers end up exporting logs and reconstructing state manually.
Why “More Connectors” Does Not Fix This
Connector count is often used as a proxy for capability. The assumption is that broader API coverage leads to better automation. Connectors define how to call an API. They do not define how execution behaves over time. A connector can handle authentication, request formatting, and response parsing. It cannot track whether a previous step succeeded in a prior execution. It cannot decide whether a retry should skip or repeat an operation.
This becomes clear in multi-step workflows. Each connector operates independently, unaware of the broader execution context. Consider a workflow that spans five systems. Each connector successfully executes its step when called. Failures occur between steps, not within them. The system needs to coordinate execution across connectors, not just invoke them.
Adding more connectors increases coverage but does not address coordination. It increases the number of possible failure points without improving the system’s ability to recover from them. Some platforms introduce conditional logic or retry policies at the connector level. That helps in isolated cases but does not solve cross-step dependencies.
Connectors operate at the API boundary, while workflow correctness depends on execution state across boundaries. Hyperautomation enters at this layer. It treats the workflow as a long-lived entity that spans connectors, retries, and external conditions. The next section moves into how that shift changes execution modeling.
What is Hyperautomation Beyond iPaaS?
The transition from iPaaS to hyperautomation starts with how a workflow is represented in the system. Instead of treating execution as a one-time chain of API calls, the workflow becomes a long-lived entity that exists beyond a single run. That change affects every part of execution. Retries are no longer independent attempts. They become continuations of an existing workflow instance. Failures are not terminal states. They are checkpoints that determine what happens next.
In practical terms, a workflow gains identity. Each execution carries a unique context that persists across time, retries, and external interactions. The system does not ask “did this step fail,” it asks “what has already been completed and what remains.” This shift also changes how engineers reason about automation. Instead of designing linear flows, they design execution paths that can pause, resume, branch, and recover without re-running completed work.
Platforms like Adopt AI position hyperautomation around this idea of persistent execution. Their approach focuses on modeling workflows as state-aware systems rather than collections of triggers and connectors.
Modeling Workflows as Execution Graphs Instead of Chains
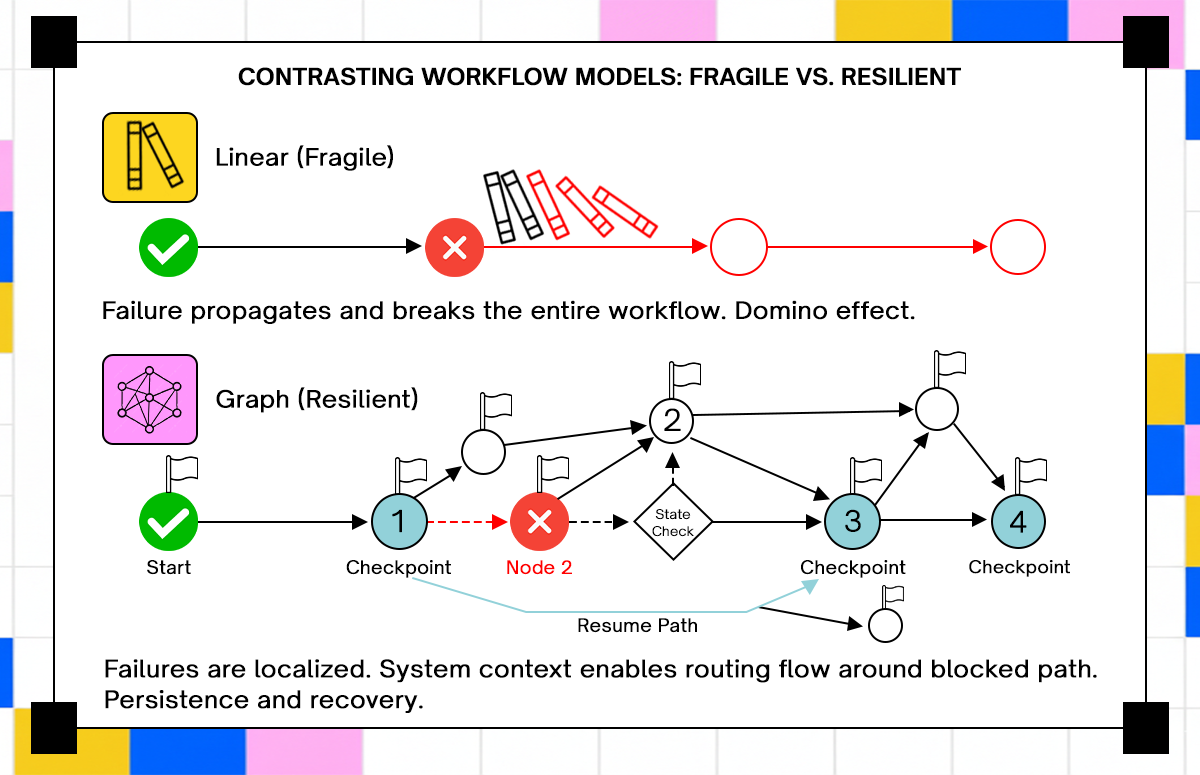
A linear chain assumes that every step executes in a fixed order and that failure stops execution entirely. That assumption breaks under real-world conditions where steps may need to retry, branch, or wait for external signals.
An execution graph models workflows as nodes and transitions. Each node represents a step, and transitions define how the workflow moves based on outcomes. This allows multiple execution paths; A success path continues forward. A failure path may retry, branch into compensation logic, or pause until conditions change.
For example, consider a supply chain workflow that processes purchase orders. After creating an order, the system checks supplier availability. If inventory is available, it proceeds to fulfillment. If not, it branches into a backorder process that waits for restock events. A linear chain cannot represent that behavior cleanly. It either blocks execution or requires external systems to trigger new workflows.
An execution graph keeps the workflow alive. It transitions between states based on events and conditions. The workflow does not end until all required paths complete. This model also supports parallel execution. Independent steps can run concurrently while sharing the same execution context. When one branch fails, only that branch needs recovery, not the entire workflow. Graph-based execution introduces complexity in orchestration, but it matches how real systems behave. External dependencies do not follow a single timeline. Workflows need to adapt to that variability without losing track of progress.
Handling Retries Without Breaking Data Integrity
Retries are unavoidable, but their behavior determines whether a system maintains consistency or introduces corruption.
A correct retry mechanism must answer two questions before executing:
- Has this step already been completed successfully?
- If retried, will it produce the same result or a conflicting one?
Without state, the system cannot answer either question reliably. In a stateful workflow, retries operate on stored execution context. Each step records its outcome along with identifiers that allow safe re-execution. Consider a payment workflow using idempotency keys. Each charge request includes a unique identifier tied to the workflow instance. If a retry occurs, the payment provider recognizes the identifier and avoids duplicate charges.
The workflow must store that identifier and associate it with the execution state. Without that linkage, retries cannot enforce idempotency consistently. Backoff strategies also become state-driven. Instead of retrying immediately, the system schedules retries based on error type and external conditions. Rate limit errors trigger delayed retries, while validation errors halt execution until input is corrected.
This behavior cannot be encoded purely as retry policies. It depends on runtime context, prior outcomes, and external signals. Stateful retry handling shifts complexity from individual API calls into the workflow system itself. Engineers no longer write retry loops in application code. They define conditions, and the system manages execution based on stored state.
Code Example: Naive iPaaS-Style Workflow (Where It Fails)
A typical integration script assumes that execution is atomic and that retries are safe.
async function syncOrder(order) {
await createOrderInCRM(order);
await createInvoiceInBilling(order);
await updateInventory(order);
}
This function has no awareness of partial success. If the billing step fails after the CRM call succeeds, the system has already introduced a side effect. A retry runs the same function again. The CRM call executes again, creating a duplicate record. The workflow completes successfully on retry, but the system now contains inconsistent data. The issue is the absence of context around what has already happened.
Code Example: Stateful Workflow with Idempotency and Checkpoints
Introducing state changes how retries behave. Each step records completion, and execution resumes from the last known checkpoint.
const stateStore = new Map();
async function syncOrder(orderId, orderData) {
const state = stateStore.get(orderId) || {};
if (!state.crmCreated) {
await createOrderInCRM(orderData);
state.crmCreated = true;
stateStore.set(orderId, state);
}
if (!state.invoiceCreated) {
await createInvoiceInBilling(orderData);
state.invoiceCreated = true;
stateStore.set(orderId, state);
}
if (!state.inventoryUpdated) {
await updateInventory(orderData);
state.inventoryUpdated = true;
stateStore.set(orderId, state);
}
}
This approach avoids duplicate execution within a single process lifetime. It introduces checkpoints that prevent re-running completed steps. The limitations appear quickly. State is stored in memory, so it is lost on process restart. Concurrent executions can overwrite each other. There is no guarantee of consistency across distributed systems.
Where Traditional Orchestration Still Falls Short
Workflow engines such as Temporal and AWS Step Functions address many of these issues by providing durable execution and built-in retry mechanisms. They persist workflow state, allow long-running execution, and support complex control flow. Engineers can define retries, backoff strategies, and compensation logic within the workflow definition.
The limitation lies in how much responsibility remains with the developer. Every edge case must be explicitly modeled. If an API changes behavior or introduces a new required field, the workflow must be updated manually.
These systems operate at the orchestration layer. They ensure that defined workflows execute reliably. They do not interpret API behavior or adapt to changes automatically. In integration-heavy environments, that gap becomes significant. Engineers spend time maintaining workflow definitions instead of focusing on business logic.
Hyperautomation systems aim to move some of that responsibility into the platform. Instead of requiring explicit definitions for every scenario, they incorporate awareness of API behavior, execution context, and failure patterns into the runtime itself.
How Adopt AI Approaches Hyperautomation Differently
Execution problems in long-running workflows come from missing context at runtime. Most systems treat APIs as static contracts and workflows as predefined sequences. Adopt AI flips both assumptions.
Instead of relying on fixed connectors, Adopt AI models workflows as persistent execution units that carry state, context, and API interaction history. The system does not just execute steps, it evaluates what has already happened and what should happen next based on that history.
From their documentation and product positioning, Adopt AI focuses on three areas: runtime-aware execution, API interaction without rigid schemas, and state management that survives retries and delays.
The practical effect shows up in failure handling. When an API call fails, the system does not simply retry the same request. It evaluates the failure type, checks prior execution state, and determines whether to retry, skip, or adjust the request. This reduces the need for engineers to encode every edge case manually. Instead of writing compensation logic for each failure scenario, the platform handles common patterns such as retries, partial success, and API inconsistencies at the execution layer.
Zero-Shot API Discovery and Why It Matters
Static connectors assume that API structure is known ahead of time. That assumption fails when APIs evolve or when integrating with systems that do not provide stable schemas. Adopt AI introduces a concept described as Zero-Shot API Discovery. The idea is to interact with APIs dynamically, without requiring predefined connectors for every endpoint.
In practice, this means the system can interpret API structure at runtime. When a field becomes required or a response format changes, the workflow does not immediately break due to a missing connector update. Instead, the system adapts its interaction based on observed API behavior.
This matters in environments where third-party APIs change frequently. SaaS platforms update endpoints, introduce validation rules, and deprecate fields without coordination across all consumers. A connector-based system requires manual updates for each change. A discovery-based system reduces that dependency by learning API structure during execution. The benefit is not just reduced maintenance. It also improves resilience. Workflows continue operating even when APIs change in minor ways, which prevents cascading failures across large-scale integrations.
ZAPI and Runtime Execution Awareness
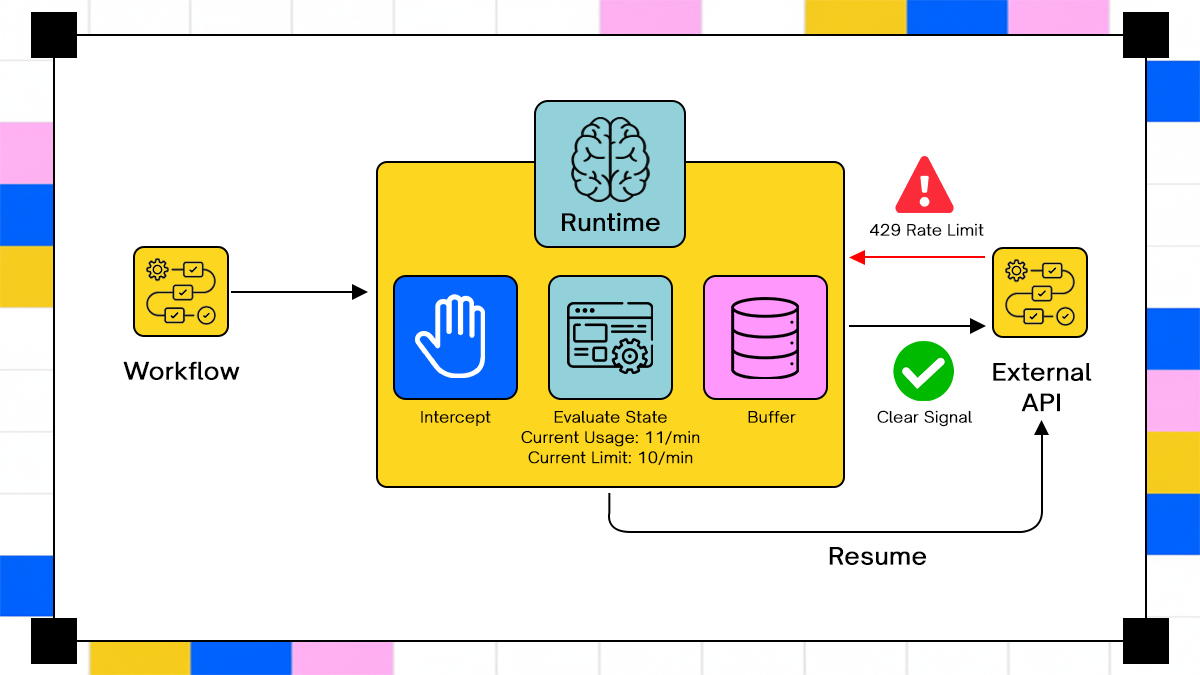
API interaction is not just about sending requests. It involves understanding how APIs behave under different conditions, including errors, retries, and partial responses. Adopt’s ZAPI layer abstracts API interaction into a runtime-aware system. Instead of treating each request as an isolated call, ZAPI evaluates requests in the context of the workflow’s execution state.
For example, if an API returns a rate limit error, ZAPI does not simply retry immediately. It adjusts retry timing based on the error and the workflow’s current progress. If a request partially succeeds, the system records that outcome and uses it to guide subsequent steps.
This approach reduces the need for static retry policies. Traditional systems rely on predefined rules such as exponential backoff. Those rules apply uniformly, regardless of context. A runtime-aware system adjusts behavior based on actual execution conditions. It distinguishes between transient failures, validation errors, and partial success scenarios. The result is more controlled execution. Instead of repeated failures followed by eventual success, the system converges toward correct outcomes with fewer redundant operations.
Conclusion
iPaaS systems work well when workflows are short, predictable, and isolated. Real systems do not fit that model once execution spans time and external dependencies.
Long-running workflows introduce state as a requirement, not an option. Without it, retries duplicate work, partial failures corrupt data, and API changes break execution at runtime.
Hyperautomation shifts execution from stateless chains into persistent systems that track progress, adapt to failures, and resume with context. Adopt AI applies this model by combining runtime-aware execution, dynamic API interaction, and state management into a single system.
Frequently Asked Questions
1. Is hyperautomation just an extension of iPaaS?
No. iPaaS focuses on connecting systems, while hyperautomation focuses on maintaining correctness across long-running execution and failures.
2. Do workflow engines like Temporal solve this problem fully?
They solve execution durability and retries, but developers still need to define behavior for API changes and edge cases manually.
3. Why do retries cause data corruption in integrations?
Retries often repeat side effects without awareness of prior success, leading to duplicate or conflicting operations.
4. Can stateless workflows be made reliable with enough safeguards?
They can be improved with custom logic, but complexity grows quickly and shifts responsibility into application code instead of the workflow system.

.svg)
.svg)


Take three minutes to find out which side of that line you are on.
Browse Similar Articles



Find Your Agentic AI Readiness Score
Every enterprise thinks they are building toward Agentic AI. But only few actually are.
Take three minutes to find out which side of that line you are on.












