Learn how Integration Platform as a Service (iPaaS) works, explore its architecture, and discover its key benefits for enterprises.



TL;DR
- Enterprise integration failures are execution failures, not connectivity failures. Retry loops, schema drift, permission changes, and partial writes cause silent data corruption long before dashboards show an outage.
- iPaaS platforms reduce risk only when execution behavior is explicit. If engineers cannot predict how a workflow behaves under timeout, restart, or human approval, the platform adds operational risk instead of removing it.
- Static connectors and stateless workflows break once systems change and processes span time. Safe integration requires a durable execution state, controlled retries, and visibility into what actually ran.
- Execution-first platforms treat integrations as stateful sequences of actions with inspectable logs and scoped access, allowing teams to reason about failures, recover safely, and audit outcomes without reconstruction.
Why Integration Becomes Hard at Scale?
An Integration Platform as a Service sits between enterprise systems to manage how applications exchange data, trigger actions, and authenticate requests without embedding that logic inside each application. In practice, iPaaS platforms provide a shared runtime for API calls, event handling, transformations, and retries, allowing organizations to connect Software-as-a-Service tools, internal services, and vendor platforms without building point-to-point code for every relationship. IBM describes iPaaS as a way to standardize and centrally operate integrations as application estates grow in size and complexity.
That centralization becomes necessary once systems reach scale. Enterprise incidents rarely originate from a single service failure because business workflows depend on chains of integrations rather than isolated applications. According to the MuleSoft Connectivity Benchmark Report, large organizations typically operate several 100+ applications, resulting in thousands of active integration paths that carry operational and financial data. Each path becomes a surface where partial failure can propagate without immediately stopping execution.
Operational postmortems reinforce this pattern; for instance, in a discussion on automated failure handling, engineers describe integration logic as "glue code" that no team explicitly owns, yet every revenue, billing, and compliance process depends on. The failure mode is usually not a crashed application, but a retry loop, a schema change, or a permission shift that went unnoticed until downstream data diverged.

Integration Platform as a Service emerged to centralize connectivity and execution under a shared runtime. Despite that promise, most enterprise integrations failures today are execution failures, not connector gaps. Understanding why requires looking at how platforms behave under real failure, which sets up the need to examine what iPaaS is actually meant to solve at enterprise scale.
Why Enterprises Centralize Integration Execution Instead of Owning It Per Team
At enterprise scale, integrations stop being peripheral mechanisms and become the execution layer for business processes that span multiple systems and teams. Customer onboarding, billing, provisioning, and compliance workflows are rarely implemented inside a single application. They are expressed as sequences of integrations that must execute correctly over time, across system boundaries, and under failure.
The motivation behind integration platform as a service was to centralize this execution layer. Instead of every team building and operating its own integration logic with local assumptions, iPaaS promised a shared runtime where execution behavior could be controlled, observed, and recovered consistently. The value of that promise becomes clear when looking at how real enterprise workflows behave once they leave the boundaries of a single service.
Example: Customer Onboarding Across CRM, Billing, and Access Control
Consider a common enterprise onboarding flow. A new customer record is created in a CRM system. That event triggers the creation of a billing account, which in turn triggers subscription provisioning and access control updates in downstream systems. Each step interacts with a different platform, often owned by a different team.
In a point-to-point model, the CRM emits an event that a billing service consumes. Billing creates an account and calls a provisioning API. Provisioning updates access control and emits a confirmation event. If billing succeeds but provisioning times out, retries may create duplicate subscriptions. If access control permissions change midway, provisioning may partially apply updates without failing the workflow outright.
From the outside, the onboarding appears complete. Internally, systems disagree about the customer’s state. Finance sees an active subscription. Access control is incomplete. Support escalations follow, and engineers reconstruct execution manually by replaying logs across systems.
Integration platform as a service exists to make this execution path explicit and centrally managed. The goal is not just to connect CRM, billing, and provisioning, but to model the workflow as a single execution unit with observable state and controlled retries.
Why Embedded, Point-to-Point Integrations Break Under This Model
Early enterprise integrations were implemented directly inside application services, scheduled jobs, or message consumers. Each integration handled authentication, retries, and error handling locally. This worked while workflows were short and failure surfaces were limited.
As workflows grew longer and crossed more systems, local assumptions began to conflict. One service retried aggressively. Another treated retries as duplicates. A third assumed ordering no longer holds. No shared execution context existed to show how work progressed across the full workflow.
Integration platform as a service introduced a shared execution layer to address this fragmentation. Authentication, retries, and transformations are now handled in a centralized runtime. Workflows could be defined once and reused, with execution visible across system boundaries.
This shift only reduces operational risk when the shared runtime behaves predictably under partial failure. If retries, state, or ordering are implicit, teams lose confidence and end up recreating point-to-point logic outside the platform.
The Operational Cost of Keeping Integration Logic Inside Applications
When integration logic remains embedded in applications, each team must independently handle retry behavior, credential rotation, schema evolution, and failure recovery. These concerns are rarely implemented consistently, especially across teams with different priorities.
During incidents, teams can explain what their service attempted, but not how downstream systems interpreted those actions or whether side effects were duplicated. Recovery often relies on manual replays or custom scripts, which increases the likelihood of data inconsistency.
Integration platform as a service aims to remove this burden by externalizing execution into a shared runtime. That goal is only met when execution state, retry behavior, and failure modes are explicit and inspectable. Whether a platform delivers on that promise becomes clear when comparing its execution model to custom integration code, which is where execution semantics start to matter.
How Integration Platform as a Service Differs From Custom Integration Code
Differences between integration platform as a service and custom integration code only become apparent when systems start failing under load, change, or over time. Build-time convenience looks similar on day one, but runtime behavior diverges once retries, upgrades, and partial failures come into play.
Understanding this difference requires examining how control is traded off for consistency and where abstraction begins to create operational risk rather than reduce it.
Control Versus Consistency in Execution Semantics
Custom integration code gives teams full control over execution ordering, retry conditions, and side effects. Engineers can model idempotence explicitly, gate retries based on business conditions, and reason about state transitions in code that lives alongside the service logic. That control comes at a cost. Each team defines its own interpretation of failure, leading to inconsistent retry behavior, uneven observability, and unclear incident ownership. Over time, production behavior depends more on who wrote the integration than on shared standards.
Integration platform as a service replaces local control with centralized execution semantics. Retries, error handling, and execution ordering follow platform rules rather than team conventions. This trade only works when those rules are explicit and inspectable. When execution semantics are hidden behind visual builders or implicit defaults, teams lose the ability to reason about failure.
When Abstraction Becomes an Operational Liability
Abstraction breaks down when engineers cannot predict what happens after a timeout, a duplicate event, or a partial write. Many platforms describe flows declaratively but execute them imperatively, which leaves operators guessing what state the system believes it is in after an error. Once behavior under retry or restart becomes unclear, engineers start bypassing the platform. Side scripts, manual replays, and out-of-band automations reappear to keep business processes running. Fragmentation returns, even though a centralized platform exists.
Adoption stalls not because platforms lack features, but because runtime behavior cannot be trusted. That failure of trust makes it necessary to look deeper at the architectural elements that define how an iPaaS runtime actually behaves.
Where iPaaS Platforms Actually Break at Runtime
Once integrations move into a shared platform, failures stop looking like coding mistakes and start looking like execution mismatches. Most iPaaS products expose similar building blocks on the surface: connectors, flows, triggers, and actions. Those labels are not where platforms differ.
Differences emerge when a workflow is already running, and something changes. An API behaves differently than expected. A retry fires after a partial write. A workflow resumes hours later with stale assumptions. Evaluating an integration platform as a service requires shifting attention from what can be modeled at design time to how execution is represented, persisted, and recovered at runtime. The following elements are where that distinction becomes visible.
Static Connector Schemas Versus Live API Behavior at Runtime
Connectors reduce setup effort by standardizing authentication and exposing a curated set of operations. In practice, they function as API proxies with a simplified schema rather than as contracts that reflect full system behavior.
Real APIs evolve continuously. New required fields are introduced. Rate limits become stricter. Defaults change. Deprecated fields remain accepted for months before enforcement tightens. Connectors often lag behind these changes because they encode a static snapshot of an API surface.
A connector continues to accept data that the live API no longer considers valid. Requests pass local validation but fail at runtime, or, worse, succeed only partially. Engineers respond by injecting custom logic or bypassing the connector entirely. Over time, the connector layer stops accurately representing reality, and correctness of execution depends on assumptions that are no longer visible or enforced by the platform. It is an execution mismatch between a static abstraction and a live system.
Designed Control Flow Versus Actual Execution During Partial Failure
Flows describe the intended sequence of steps between systems. Execution models determine what actually happens when that sequence is interrupted. Some platforms execute flows as stateless jobs. On failure, the job restarts from the beginning. Others checkpoint progress and resume from an intermediate step. Some allow explicit pause and resume across deployments. Each model makes different tradeoffs under partial failure.
Stateless execution simplifies scaling but discards context once a step succeeds and the next one fails. Checkpointed execution preserves context but introduces complexity during upgrades and version changes. Resumable workflows require explicit rules to prevent replaying outdated logic or reapplying side effects. When platforms fail to document these behaviors clearly, operators cannot safely retry or recover workflows. During incidents, teams are forced to guess whether a retry will resume, restart, or duplicate work. That uncertainty is where operational cost accumulates.
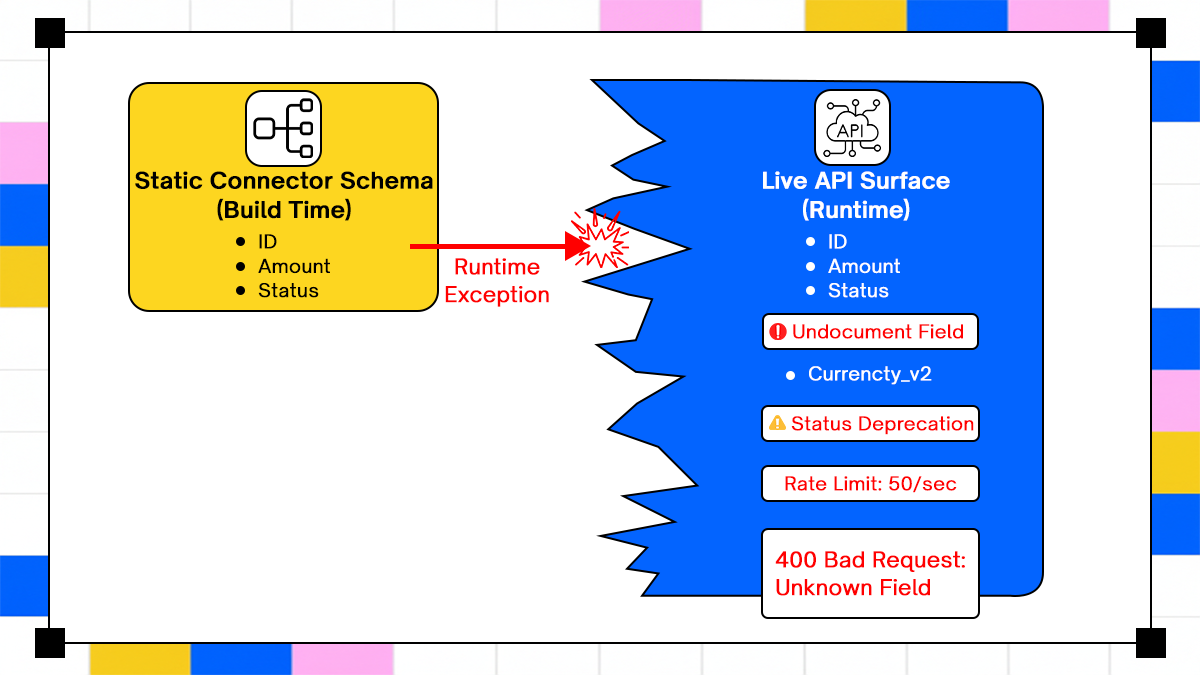
This compares the "clean" lie of a connector against the "messy" truth of a real API. A neat, static box labeled "Static Connector Schema." It lists safe, standard fields like ID,Status and Amount.
A chaotic, evolving shape labeled "Live API Surface." It shows the actual API having new required fields (e.g., Region_ID), stricter rate limits, and deprecated fields that the static connector doesn't know about. An arrow labeled "Runtime Exception" points to the gap, showing that the connector is trying to send data that the live API no longer accepts.
State Visibility and Why Implicit State Causes Incidents
State exists in every integration, regardless of whether the platform exposes it. The question is whether that state is explicit and inspectable or implicit and inferred. When the state is implicit, engineers must reconstruct what the system believes has already happened by correlating logs across systems. Stateless designs push responsibility for correctness downstream, assuming consumers can detect duplicates or reconcile inconsistencies. Fully stateful designs centralize responsibility but require careful handling of migrations, rollbacks, and versioning.
Many platforms sit in between; they expose fragments of state, enough to suggest progress, but not enough to support safe recovery. This ambiguity becomes most evident during retries, where assumptions about what has already been applied lead directly to duplicate side effects and data corruption. That failure pattern leads directly into retry semantics and idempotence, which is where execution correctness is most often lost.
Why Retries Create Duplicate Writes and Silent Data Corruption
Retries are not an edge case in enterprise integration. Network partitions, rate limiting, and transient vendor outages happen daily at scale. Any platform that does not treat retries as a first-class concern transfers risk directly to operators. Understanding retry behavior requires examining not only when retries happen, but what they do to systems that are not designed to be retried safely.
Why Retries Are the Default Failure Mode
Transient failures dominate integration errors once systems interact across organizational and network boundaries. Timeouts, throttling responses, and intermittent API failures are normal operating conditions, not exceptions.
Retrying is the only practical response, but retries amplify risk when side effects are not controlled. A retry that succeeds technically can still produce duplicate records, repeated notifications, or financial mismatches. Platforms that treat retries as a generic setting rather than a modeled behavior force teams to debug consequences after the fact.
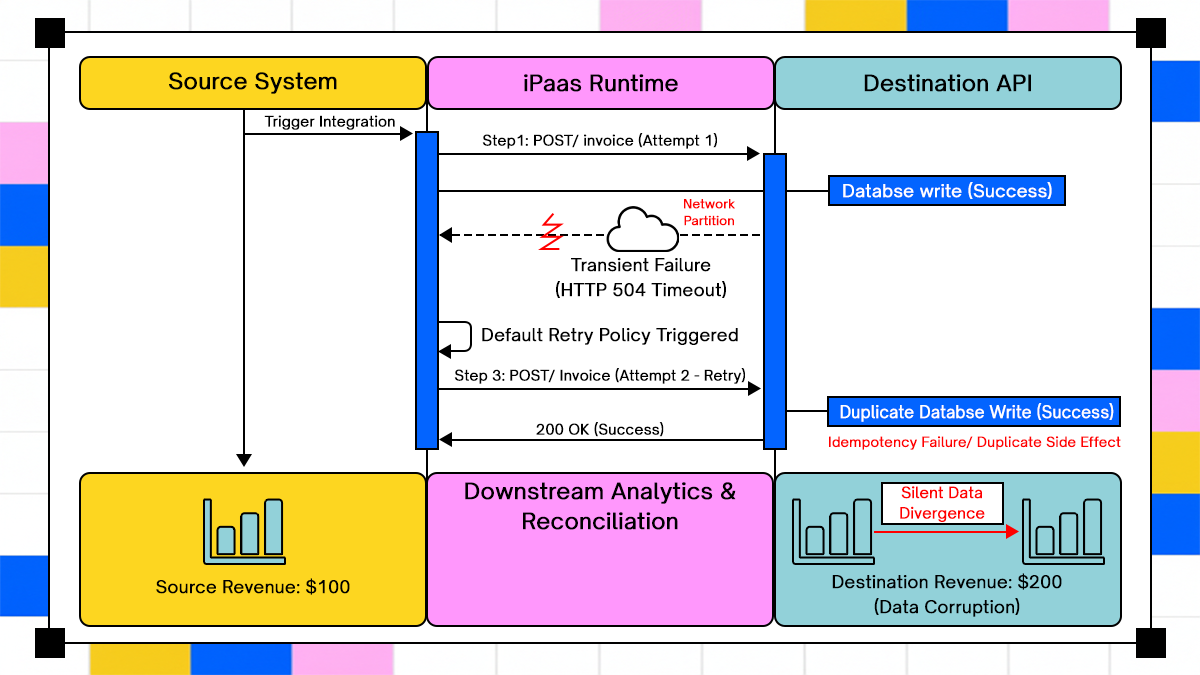
A sequence-based execution model that exposes how retry behavior actually unfolds across systems, separating the Source System, the iPaaS runtime, and the Destination API into explicit execution lanes so operators can see where responsibility shifts.
Clear representation of transient network failure at the response boundary, where the initial request commits successfully at the database layer but fails to acknowledge upstream due to a timeout or partition, creating a false signal of failure.
Automatic retry execution is driven by the default platform policy rather than the business context, issuing a second identical request that produces a duplicate write because no idempotency guard exists at the destination.
Observable divergence between system states, where the Source System reflects a single successful transaction while downstream analytics and financial records reflect duplicated side effects, resulting in silent data corruption rather than a visible outage.
Idempotence as a Design Requirement, Not a Feature
Very few enterprise integrations are idempotent by default. External systems often lack idempotency keys, and business actions like payments or approvals cannot be safely repeated. When platforms assume retries are safe, operators absorb the fallout. Incident reviews often reveal retries that appeared successful but introduced silent data divergence that surfaced weeks later.
Explicit idempotence modeling, or explicit acknowledgment that it is not possible, is required to prevent this class of failure. How platforms handle that distinction directly affects whether they can support long-running and human-dependent workflows, which is where most enterprise automation eventually breaks.
Long-Running Workflows as the Real Test of iPaaS
Short data synchronizations dominate product examples because they are easy to reason about. Enterprise work rarely fits that shape once approvals, corrections, and external dependencies are involved. Long-running workflows expose whether a platform can preserve context over time, survive restarts, and recover without manual reconstruction.
Why Short Data Syncs Are a Misleading Benchmark
Financial close processes, procurement approvals, and security exception handling depend on upstream corrections and downstream human decisions. Treating these workflows as short-lived jobs results in a loss of context when failures occur. Restarting from the beginning is often unsafe or impossible. Platforms that optimize for quick execution paths struggle once workflows cross time boundaries.
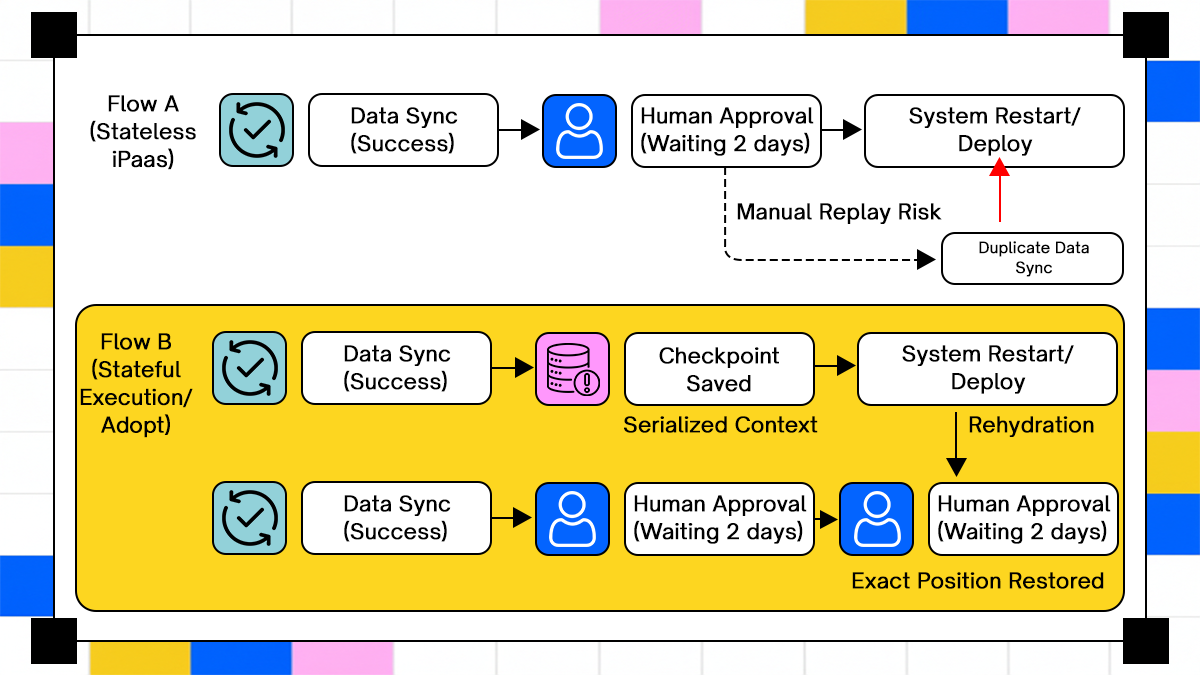
In a real enterprise environment, a three-day approval process is common in finance, procurement, and access control. A typical example is vendor onboarding. A request enters the system, validation checks run automatically, and then the workflow pauses while finance and security approvals are collected. During that pause, nothing is executing, but the workflow state must remain durable.
In a stateless iPaaS implementation, the pause is not a true state. The platform externalizes the wait into a queue, a database flag, or a human task system. When the runtime restarts due to a patch, autoscaling event, or region failover, the platform no longer knows which step completed, which checks were already applied, or what data was validated before approval. The only safe recovery path is to restart the workflow from the beginning, which forces users to reapprove or operators to manually stitch the state back together.
In a stateful execution model, the approval wait is part of the workflow state itself. When the runtime restarts, the workflow resumes in the same logical position, waiting on the same approval with the same validated inputs. No steps are replayed, no side effects are duplicated, and no manual intervention is required. The system continues as if the restart never occurred, because the execution state was preserved rather than inferred.
This distinction matters because long-running workflows are not edge cases. They are the norm for processes that involve humans, compliance gates, or external dependencies. The timeline comparison is not about convenience. It shows whether a platform can safely run enterprise workflows that span days without forcing operators to recover state by hand when infrastructure inevitably restarts.
What Actually Breaks When a Long-Running Workflow Is Interrupted
Long-running workflows appear whenever a process cannot complete within a single execution window. A common example is an access provisioning request for a production system. The request is created, automated checks run, and then the workflow pauses while security and management approvals are collected over several days.
In many platforms, this pause is not part of the execution state. The workflow is effectively parked outside the runtime. When the platform restarts due to a patch, scaling event, or regional failover, the system no longer knows which checks have already passed, which approvals are pending, or which downstream actions have already been executed. Operators are forced to restart the workflow or manually piece together the state from logs and tickets.
This is where pause, resume, and rollback stop being abstract ideas and become operational requirements. A pause that is not a durable execution state is just a delay. When the system comes back up, restarting the workflow risks duplicating side effects such as reissuing access grants or resending notifications. Skipping steps risks violating security controls because prior validations are assumed rather than known.
Rollback becomes necessary when part of the workflow has already committed state. In access provisioning, this might mean a directory group membership was granted before a later approval was denied. Without a defined rollback path, operators revoke access manually, often under incident pressure, with no guarantee that all side effects are reversed.
Platforms that lack durable pause, resume, and rollback semantics force teams to reconstruct execution state during incidents. That reconstruction is slow, error-prone, and rarely complete. Once workflows include human approvals, the problem becomes harder because decisions, corrections, and exceptions must be preserved as part of the execution state rather than inferred after the fact.
How Approval-Driven Workflows Fail When Human Decisions Sit Outside Execution
Human involvement enters enterprise automation the moment a workflow touches money, access, or compliance. A common example is the provisioning of production access. A request is created, automated checks validate the request, and then the workflow pauses while a security reviewer and a system owner approve or reject access.
At this point, the workflow is no longer purely automated, but it is still executing. The request ID, validated inputs, and pending actions already exist. If the platform treats the approval as an external interruption rather than an execution state, the system loses continuity. When the workflow resumes, the platform cannot reliably tell what assumptions were validated before the human decision was made.
What Breaks When Approvals Are Not Captured as Execution State
In access provisioning, approvals change execution behavior. A reviewer may narrow the requested scope, require additional controls, or reject part of the request. Those decisions directly affect which downstream actions are safe to execute.
When approvals are handled outside the workflow runtime, the platform resumes automation without knowing what changed or why. Operators lose visibility into which checks were revalidated and which were bypassed. During audits or incident reviews, teams cannot explain why access was granted or denied without manually correlating tickets, emails, and logs. Audit requirements make this failure mode unacceptable. Regulators and internal security teams expect systems to explain decisions, not reconstruct them after the fact.
Why Resuming Automation Requires Context, Not Just a Restart
Resuming a workflow after human input is not equivalent to restarting a job. In the access example, directory groups may already exist, reference IDs may have been issued, and downstream systems may be waiting for confirmation.
If the platform resumes blindly, it may reapply access, skip required checks, or assume conditions that were explicitly changed during approval. These errors rarely surface immediately. They appear later as excess permissions, missing revocations, or unexplained access paths.
Capturing human decisions as execution state means recording who approved, what was approved, what changed, and under which conditions the workflow continued. Without that context, accountability is lost, and failures are discovered only after damage has already occurred. This is why execution architecture matters more than tooling surface. Platforms that cannot model human decisions during execution cannot safely support enterprise workflows that span systems, time, and people.
How Adopt Approaches Integration Execution Differently
Adopt treats integration as an execution problem that unfolds over time rather than a configuration problem that can be fully defined upfront. Most platforms rely on static configurations, but Adopt uses Zero-Shot API Discovery to capture application behavior in real time. The ZAPI library records network traffic from browser sessions, creating a map of API operations from real usage. This automatic API discovery and action-generation process is described in Adopt’s core documentation, where Tools represent API primitives and Actions represent executable steps built from them.
Execution in Adopt retains explicit state across retries, pauses, and restarts. When failures occur, workflows are treated as sequences of concrete actions rather than abstract configurations, allowing operators to inspect execution logs that capture what happened, including error conditions and decision paths. Adopt’s Action Logs provide detailed visibility into execution steps, error contexts, and decision points, enabling reasoning about system behavior after the fact.
Here is a practical workflow example based on how their Open-Source Agent Stack handles a common enterprise headache: Legacy System Synchronization.
The "Zero-Drift" Inventory Sync Workflow
In this scenario, a company needs to sync stock levels between a modern storefront (Shopify) and a 10-year-old legacy ERP that has no documentation and a finicky API.
Phase 1: Zero-Shot Discovery (The Build)
Instead of spending weeks reverse-engineering the legacy ERP, a developer uses the ZAPI library to "watch" a manual inventory update.
from zapi import ZAPI# 1. Launch a browser and manually perform one inventory update
z = ZAPI()
session = z.launch_browser(url="https://legacy-erp.internal/login")# 2. Once the interaction is done, capture the network traffic (HAR)
session.dump_logs("erp_update.har")# 3. Adopt turns the HAR into an executable "Tool Card" automatically
z.upload_har("erp_update.har")
Phase 2: The Multi-Step Execution (The Run)
The workflow is now defined as a sequence of Tools and Actions. Unlike a standard script, Adopt wraps this in an Execution Layer that manages state.
- Trigger: A new order arrives in Shopify.
- Step 1 (Fetch): The agent calls the Shopify API to get the SKU and quantity.
- Step 2 (The Legacy Action): The agent uses the UpdateInventory tool generated in Phase 1 to write to the legacy ERP.
- Step 3 (Verify): The agent performs a "Read-After-Write" check to ensure the ERP database was actually updated.
Phase 3: Handling the "Silent Failure"
If the Legacy ERP times out during Step 2 (a common 504 gateway timeout), a normal script might hang or double-post. Adopt uses Action Logs to handle this:
- Context Preservation: The system records that Step 1 was successful.
- Deterministic Retry: Because the tool was generated with an understanding of the exact HTTP headers required, the system can inspect the Action Log to see if a transaction ID was sent.
- Human-in-the-Loop: If the recovery is ambiguous, the workflow "pauses" its state. An operator can see the exact error context and click "Resume" once the ERP is back online, without re-triggering the Shopify fetch.
Security and governance are applied at the level where work happens. Each action runs with scoped permissions tied to explicit access, and every executed step is recorded with context that supports compliance and audit needs. Enterprise teams rely on execution visibility and logging to trace decisions and outcomes across automated workflows without manually reconstructing intent, a need execution logs specifically address.
Conclusion
Integration platform as a service breaks down when execution is treated as an implementation detail rather than a first-class concern. In enterprise environments, failures emerge from retry behavior that was assumed to be safe, states that were never explicitly modeled, and permissions that changed without invalidating running workflows. These are not edge cases. They are the steady-state conditions under which integrations operate once systems and teams scale.
This article briefly explains integration through execution behavior rather than the tooling surface. It showed how connector abstractions leak, how stateless models collapse under partial failures, how retries amplify side effects without idempotence, and why long-running, human-dependent workflows expose the limits of configuration-driven platforms. Integration platforms that survive enterprise reality do so by making execution state explicit, failure observable, and recovery predictable. Anything else fails quietly first, then expensively.
Frequently Asked Questions
1. When does an organization outgrow basic iPaaS execution models?
Organizations outgrow basic execution models when retries, partial failures, or long-running workflows require manual reconstruction to recover. This usually occurs after integrations span multiple business systems and time windows, rather than during the initial rollout.
2. How can integration behavior be audited without slowing delivery?
Auditable integration depends on capturing execution state and actions as they occur rather than reconstructing intent after the fact. This requires logging what happened, under which credentials, and why a decision path was taken.
3. Can integration platforms as a service work in regulated environments?
Regulated environments require scoped access, traceable actions, and controlled recovery paths. Integration platforms can meet these requirements only when governance is enforced at execution time rather than through manual review.
4. What prevents integration sprawl over time?
Integration sprawl emerges when teams bypass platforms because runtime behavior is unclear or unreliable. Trust erodes when failures require manual workarounds to resolve. Clear execution semantics, visible state, and predictable recovery reduce the incentive to build side systems. When teams can reason about behavior under failure, they stay within the platform rather than work around it.

.svg)
.svg)


Take three minutes to find out which side of that line you are on.
Browse Similar Articles



Find Your Agentic AI Readiness Score
Every enterprise thinks they are building toward Agentic AI. But only few actually are.
Take three minutes to find out which side of that line you are on.












