Discover what iPaaS is and how enterprises use it to connect apps, automate workflows, and unify data across systems for faster operations.



.png)
TL;DR
- Enterprises run hundreds of applications, but most serious failures come from integrations breaking down between systems. Data gets delayed, duplicated, or dropped while moving across systems, and those failures cause the longest and hardest outages.
- The global iPaaS market reflects this pressure: it is projected to grow from roughly $19 billion in 2026 to over $108 billion by 2034, with a ~24 percent CAGR, as organizations invest to tame integration complexity.
- Having 500+ pre-built connectors doesn't matter if they can’t handle real-world errors. Real enterprise workflows run for hours or days, not seconds, and they must survive retries, partial completion, and interruptions without falling apart.
- Systems often report a successful sync while actually corrupting data. A CRM might send a record to an ERP, but if the field logic has drifted, your billing will be wrong three months later. Moving data is easy; keeping it accurate is the hard part.
- Large workflows, such as employee onboarding, always require human approval. If your integration tool doesn't treat a manager's sign-off as a core part of the process, the automation breaks and the audit trail disappears.
- Traditional tools focus on how you build a flow (the editor). Modern systems focus on how the flow actually runs (the runtime). You need a system that observes how APIs behave in real time rather than relying on brittle, hand-coded maps that break with the next update.
- Instead of relying on static, hand-coded bridges, Adopt AI uses agents that discover and act on live application surfaces. This shifts the focus from building point-in-time flows to managing live execution, giving you detailed logs of every decision and retry as they happen.
What is iPaaS?
Integration Platform as a Service (iPaaS) is a category of software that enables data movement and triggers actions between systems without writing and maintaining custom integration code for each connection. In simple terms, it sits between applications and handles how they communicate, when they communicate, and what happens when something goes wrong. Enterprises adopt iPaaS to avoid maintaining hundreds of one-off scripts that break whenever an API, credential, or data format changes.
Large enterprises routinely operate hundreds of SaaS products, internal services, and third-party platforms that must exchange data continuously to support billing, compliance, customer operations, and internal reporting. Gartner estimates that large organizations now run well over 500 applications, a number that continues to rise as teams adopt specialized tools rather than consolidated suites. Engineers reviewing incidents on Reddit communities such as r/devops and r/sysadmin consistently point out that integration failures, not core application crashes, are the hardest and longest incidents to resolve.
Integration Platform as a Service emerged as a response to this sprawl. Instead of every team writing and maintaining its own API glue, iPaaS promised a shared integration layer that centralizes authentication, data movement, and execution logic. The idea was simple: fewer bespoke scripts, more consistency, and a single place to observe failures.
That promise often breaks down in real environments because enterprise integrations are not short-lived, stateless data transfers. They are long-running, stateful processes that depend on retries, human intervention, partial success, and evolving schemas. When platforms treat these realities as edge cases rather than core concerns, reliability erodes quietly until failures become systemic.
This article examines iPaaS as a runtime system rather than a product category. The focus is on how integrations behave under load, failure, and change, and why execution architecture determines whether iPaaS reduces operational risk or simply centralizes it.
What Integration Platform as a Service Is Intended to Solve at Enterprise Scale
Enterprise integration problems accumulate as teams connect systems incrementally, solving local needs while creating global fragility that only becomes visible at scale.
From Hand-Built Point Integrations to a Growing Web No One Owns
Early enterprise integrations were built directly into application code, i.e., teams wrote scheduled jobs, message consumers, or API calls that pushed data from one system to another as needed. This approach worked when the number of systems was small and ownership boundaries were clear.
As organizations grew through acquisitions and decentralized tooling choices, these point-to-point integrations multiplied. Each new system added more credentials to manage, more schemas to reconcile, and more retry logic to maintain. Integration logic became tightly coupled to business services, making application changes risky and slowing down delivery.
iPaaS was introduced to break this coupling by moving integration logic into a shared platform. Organizations aimed to standardize how systems authenticate, exchange data, and handle failure. Integration flows could be reused, audited, and operated independently of the applications that triggered them.
This model only succeeds when the platform handles change and failure better than the code it replaces. If it does not, teams eventually reintroduce side scripts and ad hoc fixes, recreating the same sprawl inside a different tool.
How iPaaS Differs From Custom Integration Code in Practice
Custom integration code gives teams full control over execution order, error handling, and data validation. That control comes with a long-term cost. Each integration becomes a small distributed system that someone must understand, monitor, and repair when behavior changes.
iPaaS shifts this responsibility into a centralized runtime. Teams trade fine-grained control for shared execution semantics, standardized logging, and common retry behavior. In theory, this reduces cognitive load and improves reliability across the organization.
In practice, the trade only works when execution semantics are explicit and predictable. When retry behavior, state handling, or failure visibility is unclear, teams stop trusting the platform. They work around it with custom scripts, scheduled jobs, or manual intervention, slowly undermining the very consistency iPaaS was meant to provide. The difference between successful and failed iPaaS adoption is rarely the breadth of connectors. It is whether engineers can reason about what happens when something goes wrong.
Core Architectural Components That Define an iPaaS Runtime
An iPaaS runtime is shaped by how it executes integration logic once workflows are in motion, and not by how easily those workflows are assembled. At runtime, the platform is responsible for coordinating triggers, managing execution order, persisting intermediate state, and deciding what happens when any dependency fails or responds late. These responsibilities surface only under real load, when retries, partial completion, and inconsistent upstream behavior collide.
Connectors as Integration Abstractions and Their Structural Limits
Connectors attempt to standardize how systems authenticate, exchange data, and expose actions so teams do not have to reimplement the same logic repeatedly. In controlled environments with stable APIs, this abstraction reduces setup time and lowers the barrier to entry for integration work. Enterprise systems, however, rarely conform to those assumptions for long.
APIs change behavior without version bumps, fields appear only under certain account states, and rate limits vary based on usage patterns rather than documentation. Connectors often trail these changes, exposing only a subset of what the underlying system can actually do. When required fields or actions are missing, engineers compensate by embedding custom calls or transformations directly into workflows.
Once this happens, the abstraction weakens. Parts of the integration depend on connector behavior, while other parts bypass it entirely, creating uneven execution paths that are harder to observe and audit. Over time, the connector layer becomes an approximation of reality rather than a dependable interface, forcing operators to understand both the abstraction and the raw system behavior during incidents.
Connectors reduce initial effort, but they do not remove the need to reason about how external systems behave under real conditions. Treating them as complete representations leads to brittle integrations that fail quietly and recover unpredictably.
Flow Definitions, Execution Models, and State Representation
Integration flows describe what should happen, but the execution model determines what actually happens when conditions deviate from the happy path. Most platforms represent integrations as sequences of triggers, transformations, and actions connected by conditional logic. How these flows are executed in the event of failure determines their reliability.
Stateless execution models treat each run as disposable. This approach simplifies horizontal scaling but breaks down when retries occur after partial completion. Without persisted state, the platform cannot distinguish between steps that completed successfully and those that did not, so retries often restart from the beginning and reapply side effects.
Stateful execution models preserve progress between steps, allowing workflows to resume from known checkpoints. This improves correctness but introduces complexity around upgrades, versioning, and rollback, since execution state must remain compatible across changes. Platforms that expose state handling clearly allow operators to reason about recovery. Platforms that hide it force teams to learn behavior through failure.
State representation is not an implementation detail. It defines whether workflows behave deterministically under stress or degrade into repeated retries and manual fixes.
Retry Semantics, Idempotence, and Side Effect Control
Retries are unavoidable in distributed systems because networks fail, dependencies throttle requests, and upstream services respond inconsistently. The risk comes from assuming retries are harmless without validating how downstream systems react to repeated actions.
Without explicit idempotence guarantees, retries can create duplicate records, send duplicate notifications, or apply financial transactions multiple times. These issues often remain hidden until reconciliation processes surface discrepancies long after the original failure. At that point, the cost of correction far exceeds the cost of prevention.
Many iPaaS platforms treat retries as a generic mechanism rather than a design constraint that must be modeled on a per-action basis. When retry behavior is opaque, operators cannot predict side effects or reason about safe recovery paths. Responsibility shifts to humans to detect and undo damage after the fact.
Reliable integration depends on making retry behavior explicit, observable, and aligned with how downstream systems handle repeated requests. Anything less transfers risk from the platform to the people operating it.
Common Integration Failure Modes Observed in Enterprise iPaaS Deployments
Enterprise integration failures tend to repeat the same patterns, regardless of industry or tooling, because they stem from structural properties of distributed systems rather than individual implementation mistakes. A common example is an order-to-cash workflow that syncs data between a CRM, an ERP, and a billing system, running continuously as customer volume grows and systems evolve independently. These failures often remain invisible during early testing and only surface after weeks or months of real operation, when symptoms appear far downstream from the original cause.
Schema Drift and Gradual Data Corruption Across Systems
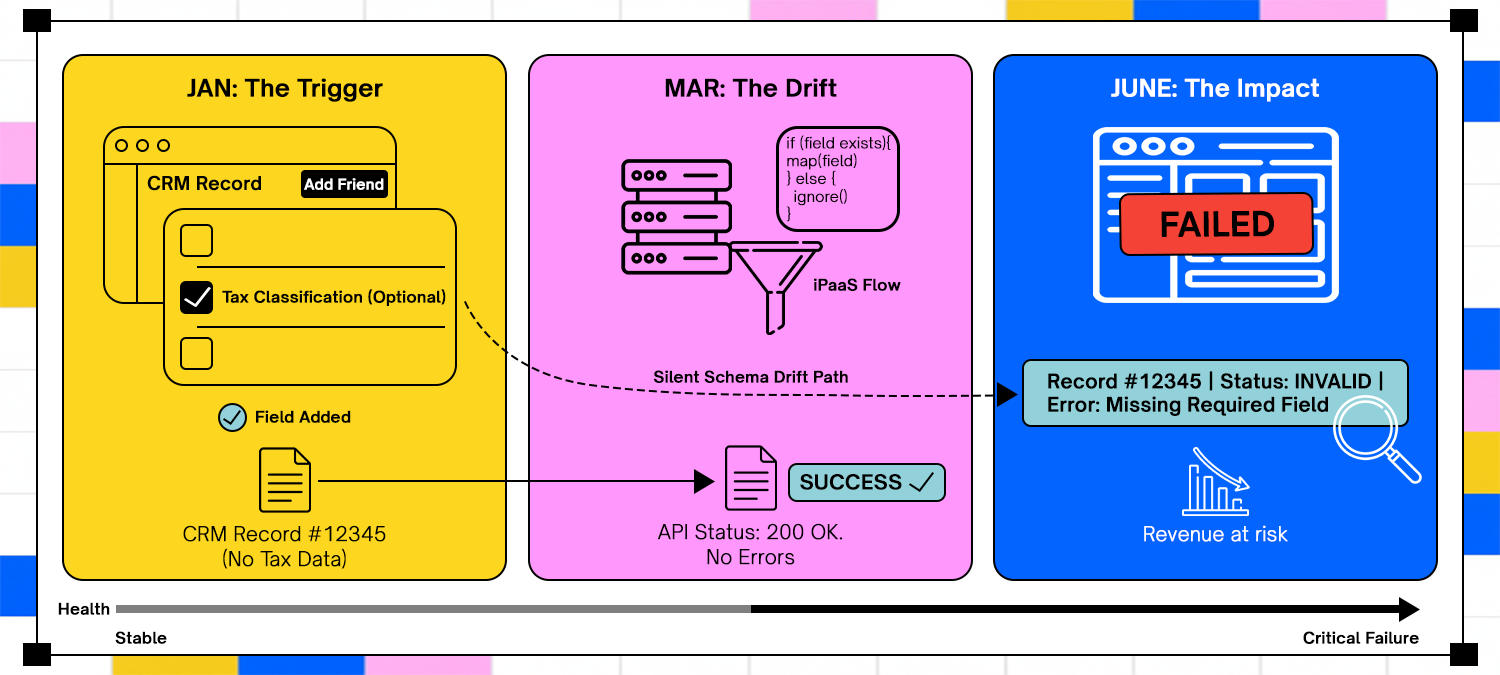
Consider a CRM pushing customer records into an ERP as part of an order workflow. A new optional field has been added to the CRM schema to capture tax classification, but the ERP integration still treats it as optional because existing records still sync successfully. Data flows uninterrupted, and no errors are raised.
Months later, the billing system begins enforcing that field for compliance reporting. Historical records synced without the field now fail reconciliation, even though the integration itself never errored. The problem is not a broken API call but a slow divergence in meaning between systems that tolerated ambiguity at different stages.
iPaaS platforms that focus on moving data rather than validating it in an execution context tend to amplify this issue. Without awareness of how downstream systems interpret fields over time, corruption accumulates silently until recovery requires reconstructing the past state across multiple systems.
Event Ordering, Duplication, and Timing Assumptions That Break at Scale
In the same workflow, order updates are propagated using events emitted from the CRM. An update event for a pricing change is delayed due to retry backoff, while a later cancellation event is processed immediately. The billing system applies the cancellation, then receives the delayed pricing update and reopens the order.
Duplicate events further complicate matters when retries replay actions that were assumed to be safe. Notifications are sent twice, invoices are regenerated, and downstream systems drift out of sync. None of these failures is catastrophic on its own, but together they erode trust in automation.
Handling this correctly requires tracking execution state across events rather than reacting to each event in isolation. Platforms that treat events as independent triggers lack the context to determine whether an action remains valid, turning timing variance into operational noise at scale.
Credential Expiry and Access Scope Decay Over Time
As the workflow matures, security teams rotate credentials and tighten the scope of the ERP integration. The integration retains read access but loses permission to create adjustment entries. Order ingestion continues, but updates silently fail, leaving records partially processed.
Because authentication does not fail outright, the workflow appears healthy at a glance. The issue surfaces weeks later when finance teams notice discrepancies between CRM and ERP data. By then, the problem is not a single failure but a backlog of inconsistent states.
Platforms that only surface credential errors at execution time miss these gradual degradations. Treating credentials as part of the runtime state, including their scope and validity, enables detection of access decay before it disrupts business processes.
Long-Running and Human-Dependent Workflows as a Stress Test for iPaaS
Long-running workflows surface failure modes that short-lived integrations never encounter. A typical example is enterprise employee onboarding, where an accepted offer triggers account creation across identity systems, device provisioning, payroll setup, and compliance checks that unfold over several days. Each step depends on the successful completion and interpretation of the previous one, even as retries, updates, and manual intervention occur.
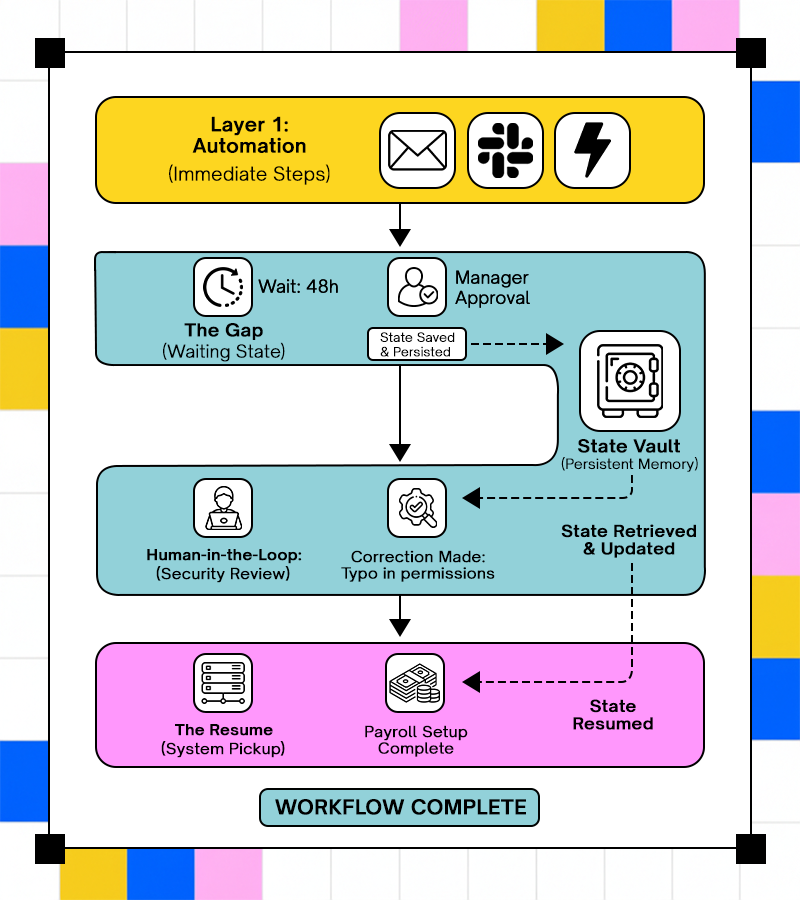
Why Short-Lived Data Syncs Do Not Represent Real Enterprise Work
Short-lived data syncs make convenient examples because they complete within seconds. A user record is created in an HR system and copied to an identity provider, and the integration appears successful. This pattern hides the complexity present in the full onboarding workflow.
In a real onboarding flow, identity creation may succeed immediately, while device provisioning waits for manager approval and payroll setup pauses until tax information is available. A background check mighttake hours to complete, hours later, and alter eligibility, forcing the workflow down a different path. Treating this process as a sequence of immediate syncs ignores the fact that execution must pause, branch, and resume in response to external input.
When platforms model all work as immediate execution, waiting becomes indistinguishable from failure. Operators lose visibility into whether a workflow is blocked by design or stuck due to an error. Over time, teams stop automating these processes because manual coordination feels more reliable than the opaque behavior of systems.
Human-in-the-Loop Steps as First-Class Workflow State
Human intervention is a built-in requirement in workflows like onboarding. Managers approve access levels, security teams review exceptions, and HR corrects missing information. These actions are not interruptions; they are part of the workflow’s expected path.
When platforms push these steps outside the execution model, context fragments. The system pauses, humans act through email or tickets, and automation resumes without understanding what changed or why. In onboarding, this often results in over-provisioned access, repeated approvals, or accounts created with incorrect entitlements.
Treating human actions as explicit state transitions preserves intent and accountability. Operators can see why onboarding was paused, what decision was made, and how execution continued afterward. This visibility turns human involvement into a controlled component of automation rather than a hidden dependency that erodes trust.
Why Traditional iPaaS Architectures Break Under Real Enterprise Change
Traditional iPaaS architectures were shaped by environments where integrations were predictable, APIs changed slowly, and workflows could be fully described upfront. Enterprise environments no longer behave that way, but most execution models still assume they do. As systems evolve, these assumptions surface as structural limits rather than isolated bugs.
A common example is a revenue operations workflow that syncs deals from a CRM into an ERP and a billing system. The flow is defined once, tested successfully, and rolled out globally. Over time, discount rules change, new deal types are introduced, and regional compliance logic is added. The original flow still runs, but it no longer reflects how the business actually operates.
The failure modes tend to cluster around three architectural constraints:
- Static flow definitions
Logic is encoded in advance and redeployed whenever behavior changes. When a new deal structure or exception appears, teams must modify and redeploy shared flows, often coordinating across multiple consumers. Under time pressure, they bypass the platform with scripts or manual fixes, fragmenting execution.
- Tool-centric design over execution behavior
Platforms emphasize how integrations are built through editors and templates, but treat runtime behavior as something to inspect after failure. Execution data is logged but not used to adapt logic, retries, or validation rules. Each incident is resolved manually, while the system repeats the same mistakes later.
- Lack of runtime learning
The platform does not improve based on observed outcomes. A failed pricing sync today is handled the same way as it was six months ago, even if the root cause is well understood. Teams fix symptoms, not patterns, and reliability plateaus.
In the CRM-to-ERP example, this results in multiple versions of the same integration running in parallel, each handling a slightly different edge case. Audits become harder, behavior becomes unpredictable, and trust in automation erodes.
Adopt’s Execution-First View of iPaaS
Adopt.ai centers automation on how integrations behave at runtime rather than solely on how flows are defined. The platform offers agents that execute multi-step workflows across SaaS applications, on-prem systems, and data sources. These agents act on discovered APIs and structured actions, which reduces the friction of writing custom integration code.
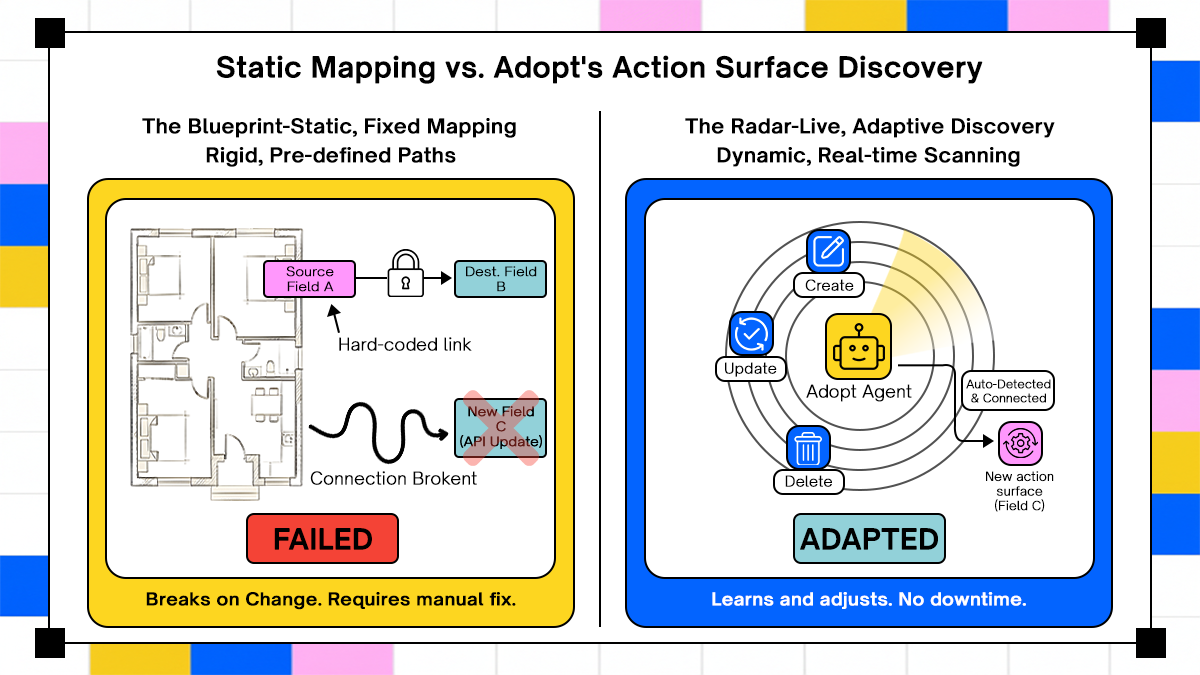
This runtime perspective shifts effort away from building point-in-time flows toward managing execution, error handling, and outcomes as they occur. Because workflows can involve multiple systems and dependencies, operators benefit from execution visibility rather than relying only on design-time correctness.
Agent-Based Execution Against Real Application Action Surfaces
Adopt.ai generates actionable surfaces for applications by discovering APIs and structuring actions that agents can invoke. This contrasts with approaches that depend only on static connector definitions.
By running against actual action surfaces, agents can coordinate complex tasks across systems without extensive hand-coded bridges between platforms. This enables workflows that span CRM, ERP, and other enterprise systems to execute operations in sequence.
Validation and Observability Through Execution Data
Adopt.ai captures detailed execution logs that record every step an agent takes, including decisions, errors, and outcomes. These logs serve as the primary audit trail for observing how workflows behaved in production.
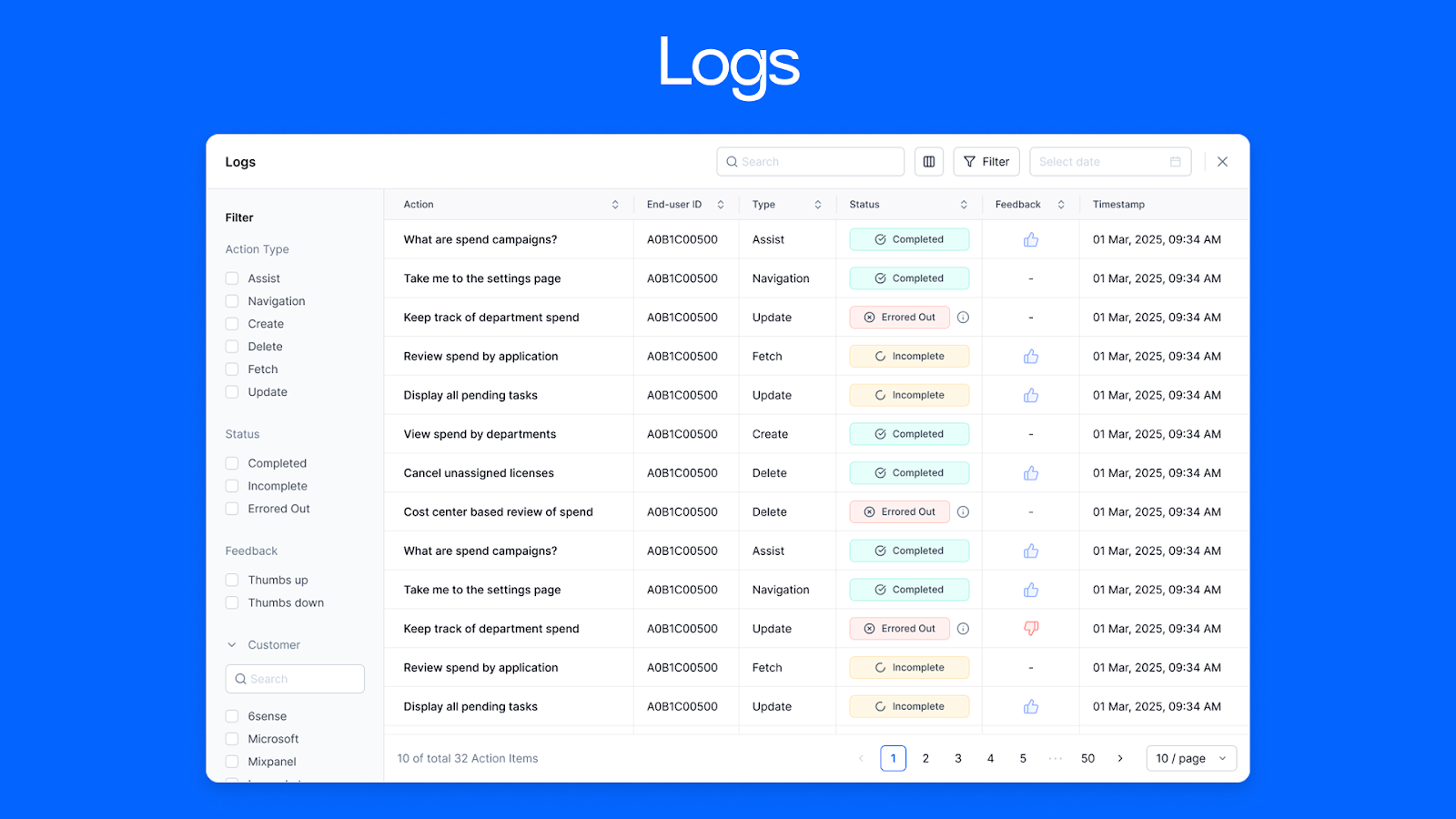
Operators can inspect execution traces to understand why a workflow stalled, which dependency caused a failure, or how retries played out. This moves debugging and compliance investigations from inferred behavior based on definitions to evidence based on actual execution.
Security, Governance, and Audit in Automated Execution
The platform advertises governance surfaces and full observability, indicating that security and audit requirements are integral to its execution model.
Comprehensive execution logs provide the context needed to reconstruct what happened, who initiated an action, and how it unfolded. These capabilities support compliance and traceability without relying on separate reconciliation processes afterward.
Conclusion
iPaaS succeeds or fails based on how well it handles reality rather than how cleanly it models intent. Enterprise environments change continuously due to API drift, access changes, operational exceptions, and human intervention that cannot be predicted at design time. Platforms that treat integration as a static configuration problem inevitably push complexity onto operators, who then compensate with manual work and side systems.
An execution-first approach reframes integration as an ongoing operational system with explicit state, observable behavior, and governed action. This framing does not remove complexity; it makes it visible and controllable. The difference shows up during incidents, audits, and recovery, when teams need evidence rather than assumptions.
Integration reliability is not achieved by adding more connectors or visual builders. It is achieved by treating execution semantics, state, and governance as core infrastructure concerns and designing for failure from the start. Adopt AI applies this model by grounding integrations in runtime execution, using agents that act on real application actions and produce durable execution logs, so teams can operate integrations as systems rather than diagrams.
Frequently Asked Questions
1. When does an enterprise outgrow traditional iPaaS execution models?
Enterprises outgrow traditional models when integrations stop behaving like short-lived jobs and become long-running processes with dependencies, approvals, and retries that span hours or days. At that point, stateless execution and opaque retries create more risk than they remove. The tipping point usually appears as repeated incidents that require manual reconstruction rather than simple reruns.
2. How can teams audit automated integrations effectively?
Effective auditing depends on capturing execution behavior rather than inspecting configuration. Teams need to see what actions were taken, in what order, with which inputs, and under which permissions. Configuration snapshots alone cannot answer these questions once systems change or data evolves.
3. Can iPaaS operate in regulated environments without slowing delivery?
Yes, iPaaS can operate in regulated environments when governance is embedded into execution rather than layered on afterward. Scoped permissions, durable logs, and explicit state transitions allow automation to proceed without bypassing controls.
4. How do organizations prevent integration sprawl over time?
Preventing sprawl requires ownership and lifecycle discipline rather than stricter tooling rules. Each workflow must have a clear owner, a defined purpose, and an agreed retirement path when it no longer serves that purpose.

.svg)
.svg)


Take three minutes to find out which side of that line you are on.
Browse Similar Articles



Find Your Agentic AI Readiness Score
Every enterprise thinks they are building toward Agentic AI. But only few actually are.
Take three minutes to find out which side of that line you are on.












