Discover how enterprises use workflow automation to streamline end-to-end processes, reduce manual tasks, boost efficiency, and improve productivity.



TL;DR
- Large enterprises struggle to scale workflow automation because most tools cannot reliably coordinate execution across multiple systems with different failure and timing characteristics.
- Treating workflows as chained tasks rather than long-running systems leads to broken state, unsafe retries, and hard-to-diagnose production issues.
- Idempotence and explicit state management are required to keep distributed workflows safe when retries and partial failures occur.
- Most production failures surface as silent inconsistencies caused by integration drift, asynchronous execution, and missing observability.
- Adopt AI addresses these execution challenges by grounding workflows in real backend behavior and validating them through live execution rather than static definitions.
Despite years of tooling improvements, many enterprises encounter persistent failures when they attempt to automate cross-department, cross-system processes. According to a Gartner-cited survey, about 62 percent of large organizations start with departmental pilots that never become enterprise-wide programs because tools remain isolated and lack cross-system coordination.
This fragmentation has shifted market expectations; recent research on B2B SaaS expectations for 2026 suggests that the primary value of new software is no longer just "adding a feature," but how well it integrates into these messy, multi-vendor ecosystems.
A recent discussion on r/devops regarding the hidden costs of integration debt highlights how teams are struggling to maintain "perfect" automated flows.
One practitioner noted that their attempt to link HRIS and identity platforms resulted in a revert to manual checkpoints after silent schema updates from a third-party API broke downstream payroll provisioning. While the individual tools functioned correctly, the lack of a shared state meant that small failures in one system created data inconsistencies that took weeks to detect.

Real failures occur among practitioners who try to automate beyond simple tasks and reach long, multi-system chains. These real-world reports underscore that enterprise automation must manage state, dependencies, and unpredictable inputs in ways that most tools and patterns today do not. This article examines the anatomy of enterprise workflows, identifies where they fail, and analyzes design patterns that sustain production workloads.
Anatomy Of Enterprise Workflows
Enterprise workflow automation begins to fail when teams treat workflows as a loose collection of automated tasks rather than as long-lived systems that must coordinate state, logic, and execution across multiple technical and organizational boundaries. Before examining failure modes or architectural trade-offs, it is necessary to define what constitutes a workflow in an enterprise environment and how it differs from adjacent automation approaches.
This distinction matters because most production incidents tied to automation originate from incorrect assumptions about how workflows behave once they cross system boundaries, interact with humans, or encounter partial failures.
What Constitutes A Workflow In The Enterprise
In enterprise systems, a workflow is a coordinated sequence of actions that spans multiple systems, persists state over time, and applies decision logic at each transition. Unlike task automation, which focuses on executing a single action in isolation, or process automation, which often models idealized business flows, enterprise workflows must operate under real conditions where systems fail independently, and data arrives out of order.
Workflow automation is best understood as the combination of sequence, state, and logic applied across heterogeneous systems. The sequence defines the order in which actions occur, the state captures where the workflow currently stands and what has already happened, and the logic determines how the workflow responds to data, events, or human input at each step. When any of these elements are implicit rather than explicit, workflows become difficult to reason about and harder to recover when failures occur.
At a practical level, enterprise workflows are composed of several core components that appear consistently across domains such as finance, identity management, customer operations, and internal tooling.
Triggers initiate workflows based on system events, scheduled conditions, or explicit human actions, such as a submitted form or an approval decision. Routing logic evaluates conditions and determines which execution path the workflow should follow, often branching based on data quality, policy constraints, or contextual signals. Execution steps perform concrete actions across systems, such as calling APIs, updating records, or provisioning resources, each of which introduces external dependencies and potential failure points. Monitoring, logging, and audit trails provide visibility into workflow progression and serve as the foundation for troubleshooting, compliance, and post-incident analysis.
These components form a distributed control system rather than a linear script. When they are treated as such, workflows can be designed to survive retries, delays, and partial system outages. When they are not, automation remains fragile and difficult to operate at scale.
Enterprise Integration Challenges
Once workflows extend beyond a single application, integration complexity becomes the dominant constraint on reliability. Enterprise environments typically combine modern APIs with legacy systems, custom integrations, and asynchronous messaging patterns, each with its own assumptions about data formats, timing, and error handling.
The integration surface expands quickly as workflows span customer relationship management systems, enterprise resource planning platforms, identity providers, ticketing tools, and internally developed services. Each integration point carries its own schema expectations, authentication mechanisms, and rate limits, and these differences compound as workflows grow longer and more interconnected.
Common enterprise application integration failure patterns include:
- Mismatched data schemas that evolve independently across systems, inconsistent error signaling that obscures whether an operation failed or partially succeeded, and silent data drops where messages are lost without triggering retries or alerts. These failures rarely present as immediate errors and instead surface as downstream inconsistencies that require manual investigation to diagnose.
- Organizational constraints further complicate integration. Security policies enforce least-privilege access, network segmentation restricts direct communication between systems, and compliance requirements mandate logging and traceability. While these constraints are necessary, they increase the coordination cost of automation and expose weaknesses in tooling that assumes unrestricted connectivity or static credentials.
Traditional Techniques And Their Limits
Many enterprises begin their automation journey with rule-based systems or Robotic Process Automation because these approaches promise quick wins with minimal engineering effort. In controlled environments with stable interfaces, these techniques can reduce manual work and improve consistency for narrowly scoped tasks.
Rule-based automation relies on predefined conditions and actions that execute deterministically when inputs match expected patterns. This approach works well when data structures are stable and decision logic is simple, but it becomes brittle as workflows encounter ambiguous inputs, evolving schemas, or complex branching requirements.
Robotic Process Automation extends automation into user interface interactions by mimicking human actions such as clicking buttons or entering text. RPA systems often succeed in automating legacy applications that lack APIs, but they depend heavily on interface stability and lack semantic understanding of the underlying business context. When user interfaces change or backend behavior shifts, RPA workflows tend to fail abruptly and require manual reconfiguration.
Low-code workflow engines address some of these limitations by offering visual modeling tools and reusable connectors, enabling teams to assemble workflows quickly for fixed patterns. These platforms reduce initial development effort and lower the barrier to entry for non-engineers, which makes them attractive for early automation initiatives.
Their limitations become apparent as workflows grow in complexity. Static logic struggles to accommodate dynamic decision-making, and limited observability makes it difficult to trace execution across systems during failures. As a result, low-code workflows often reach a ceiling where additional complexity increases operational risk faster than it delivers value.
Enterprise Workflow Orchestration Patterns
Once workflows span multiple systems, orchestration becomes the core technical challenge. Orchestration defines how workflows are triggered, how state transitions are coordinated, and how execution behaves when systems respond late, partially, or incorrectly. The patterns chosen here determine whether workflows remain predictable under load or degrade silently over time.
Trigger And Event Models
Workflow execution begins with a trigger, and the trigger model determines how reliably workflows observe changes in the environment. Enterprises typically rely on either polling-based or event-driven mechanisms, each introducing different trade-offs that affect latency, consistency, and failure recovery.
Polling-based automation periodically queries systems to detect state changes. This approach is simple to implement and works with systems that lack event emission, but it introduces inherent delay and increases load on upstream services. Polling also struggles to capture short-lived states and can miss transitions that occur between polling intervals.
Event-driven automation reacts to signals emitted by systems when changes occur. This model reduces latency and load, but it relies on reliable event delivery and correct ordering. In distributed environments, event-driven workflows must operate under eventual consistency, where systems may observe events at different times or in different sequences.
Common failure modes in trigger and event models include:
- Missed events caused by transient outages or misconfigured subscriptions.
- Out-of-order event delivery that advances workflows incorrectly.
- Duplicate events that trigger repeated execution of the same step.
Idempotence And State Management
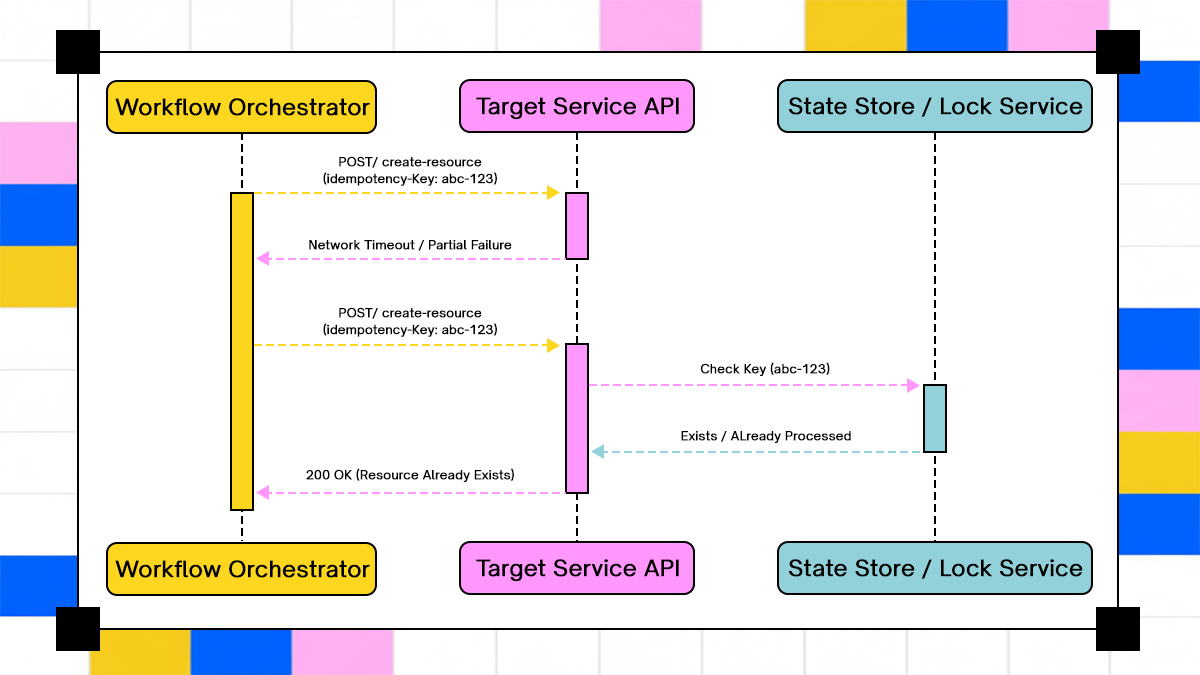
An idempotent execution pattern prevents duplicate resource provisioning during retries by checking the operation state before execution.
As workflows interact with unreliable networks and external services, retries become unavoidable. Idempotence ensures that repeating an action produces the same result as executing it once, which is essential for safe retries in distributed workflows.
Idempotent actions prevent workflows from corrupting state when retries occur due to timeouts or partial failures. Without idempotence, retries can duplicate side effects such as provisioning resources twice, issuing duplicate access grants, or creating inconsistent records across systems.
A common retry scenario in enterprise workflows illustrates this risk. A workflow step submits a request to provision access in an identity system and times out before receiving a response. If the workflow retries without verifying whether the original request succeeded, the system may execute the transition twice, producing conflicting or redundant state.
Effective state management combines:
- Explicit workflow state tracking rather than inferred progression.
- Idempotent execution guarantees for each step.
- State reconciliation mechanisms that verify outcomes before advancing.
These practices allow workflows to recover safely from partial failures without introducing new inconsistencies.
Exception Handling And Human-In-The-Loop
Not all workflow failures are equal, and effective orchestration requires classifying exceptions rather than treating them uniformly. Exception-handling strategies depend on the nature of the failure and the degree of automation required for resolution.
Enterprise workflows commonly encounter three classes of exceptions:
- Transient system errors, such as temporary network failures or rate limits, can often be resolved through retries.
- Data inconsistencies, such as missing or invalid fields, which require validation or correction before proceeding.
- External dependency failures, such as third-party service outages, may require pausing execution or rerouting workflows.
Human-in-the-loop mechanisms introduce controlled intervention points where automation cannot proceed safely. These mechanisms support escalation paths, rollback decisions, and approval workflows, while preserving auditability and traceability.
Effective exception handling designs ensure that human intervention is deliberate and visible, rather than an implicit fallback when automation silently stalls.
AI Agentic Workflow Approaches
As workflows grow more complex, some enterprises introduce AI-driven decision-making to handle variability that static rules cannot capture. These approaches modify how workflows interpret context, route execution, and respond to ambiguous inputs, but they also introduce new architectural constraints that must be managed carefully.
How AI Changes Workflow Execution
Traditional rule engines execute predefined logic based on explicit conditions. Their behavior is predictable and auditable, but they struggle when decision boundaries depend on unstructured data or evolving context.
AI-driven decision models evaluate inputs probabilistically and dynamically infer intent or classification. This allows workflows to adapt to data variations and handle scenarios that are difficult to encode with fixed rules, such as interpreting free-text requests or categorizing support tickets based on semantic content.
Research into AI-assisted automation highlights both strengths and limitations. Studies show that AI systems can improve routing accuracy and exception handling in dynamic environments, but they also exhibit failure modes tied to data drift and model misinterpretation that can affect long-running workflows over time. These challenges complicate reliability and reset behavior when workflows must return to known-good states after errors.
Architectural pitfalls observed in AI-driven workflows include:
- Classification errors are introduced as input data distributions change.
- Semantic misunderstandings where inferred intent diverges from operational requirements.
- Difficulty reproducing decisions during audits or incident investigations.
These issues do not invalidate AI-based approaches, but they demand stricter controls than traditional automation.
When To Introduce AI Into Automation
AI-driven decision-making is most appropriate when workflows encounter complexity that cannot be captured by deterministic logic. These include scenarios where inputs are unstructured, ambiguous, or highly variable across contexts.
Examples include dynamic routing of service requests based on textual descriptions or prioritizing incidents based on inferred impact rather than fixed severity codes. In these cases, AI can reduce manual triage effort and improve responsiveness when supported by strong guardrails.
Introducing AI into workflows requires addressing specific risks:
- Model correctness must be evaluated against compliance and policy constraints.
- Decisions must be logged with sufficient context to support audit and review.
- Explainability mechanisms must exist to justify the choice of a particular path.
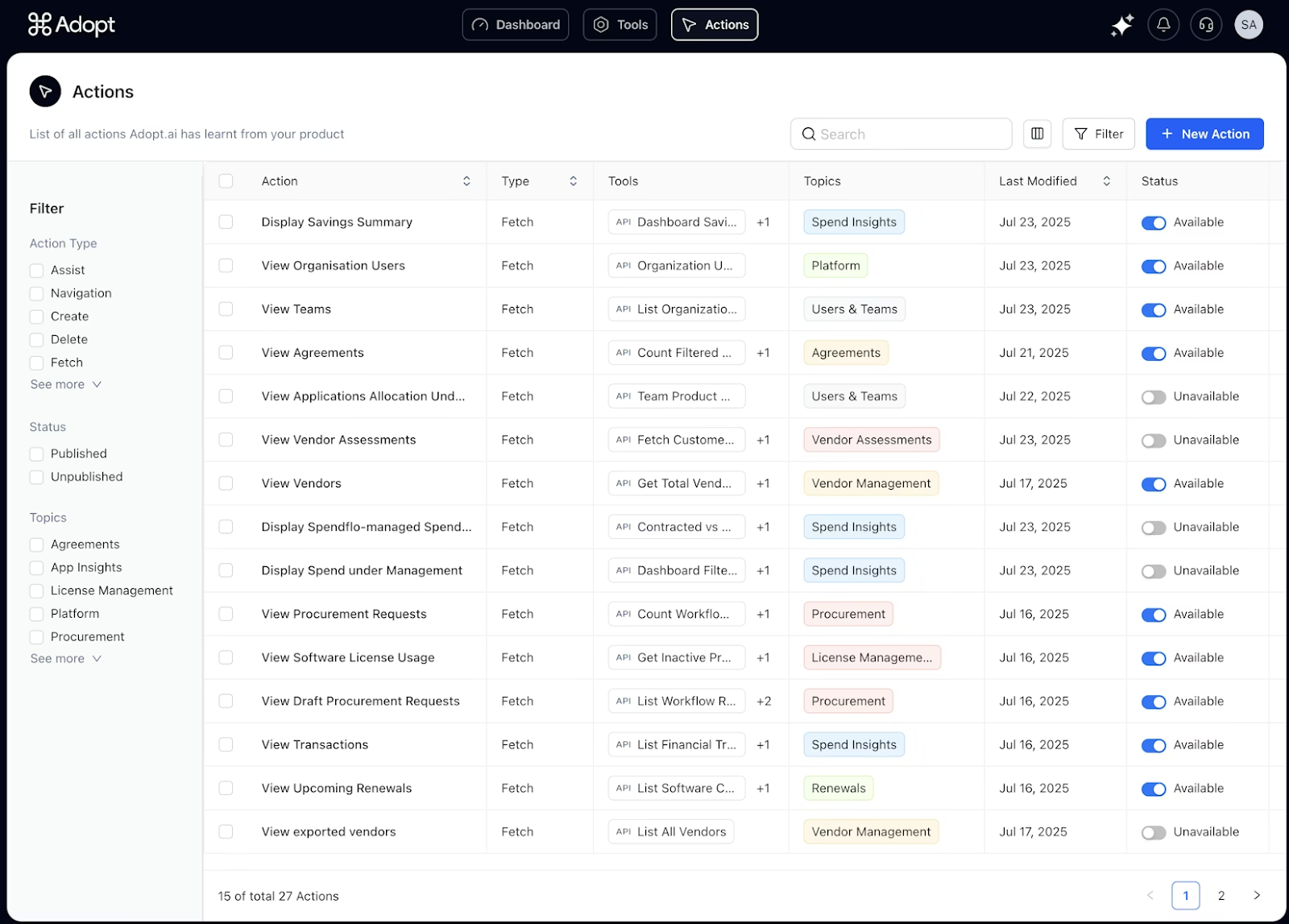
Where Workflows Fail In Production
Once workflows leave controlled environments and begin operating continuously across multiple systems, failure patterns emerge that are rarely visible during design or pilot phases. These failures are not caused by a single broken component, but by the interaction between systems that evolve independently, respond asynchronously, and fail in partial, non-obvious ways.
Hidden Failure Modes
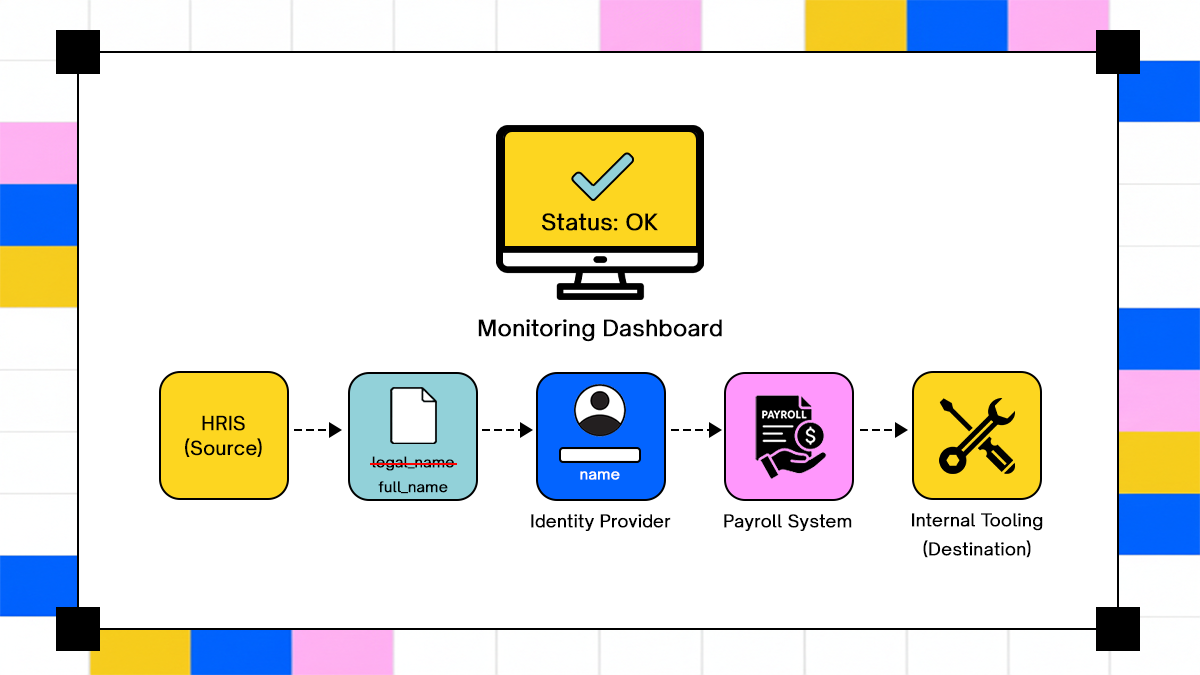
How an upstream schema change can cause silent data corruption across a multi-system workflow, often evading standard monitoring tools.
Production workflows accumulate edge cases as integrations change, scale increases, and execution paths diversify. Many of these failure modes do not surface as explicit errors and instead manifest as silent inconsistencies that propagate downstream.
Common integration edge cases include:
- Mismatched schema versions where upstream systems add or rename fields without coordinating with downstream consumers.
- API throttling that degrades performance gradually, causing workflows to stall rather than fail fast.
- Expired or rotated credentials that invalidate long-running workflows midway through execution.
Asynchronous execution further compounds these issues. In distributed environments, one microservice may complete an operation after a delay while another proceeds based on an earlier assumption of completion. This creates an inconsistent workflow state, where different systems hold conflicting views of progress, making recovery difficult without manual reconciliation.
These failures often remain undetected until a secondary system behaves unexpectedly, at which point tracing the original cause requires reconstructing execution across logs that were never designed to align.
Monitoring And Observability Gaps
Effective remediation depends on visibility, yet most workflow automation systems provide limited insight into how workflows behave across multiple services. Instrumentation typically focuses on individual steps rather than the end-to-end execution path.
Blind spots commonly observed in enterprise workflows include:
- Lack of cross-system trace correlation that links actions across services into a single execution narrative.
- Absence of perceptive metrics that describe workflow health, such as duration at each step or time spent waiting on external dependencies.
Without these signals, operators cannot distinguish between a slow workflow and a stalled one. Issues surface indirectly through downstream symptoms, such as delayed approvals or missing records, rather than through explicit alerts tied to workflow state.
Adopt’s Role In Workflow Execution Architecture
As enterprises encounter the limits of static automation approaches, agent-based execution models emerge as a way to handle variability across systems and execution paths. Adopt fits into this architectural layer by focusing on how workflows are executed and validated rather than how they are visually modeled.
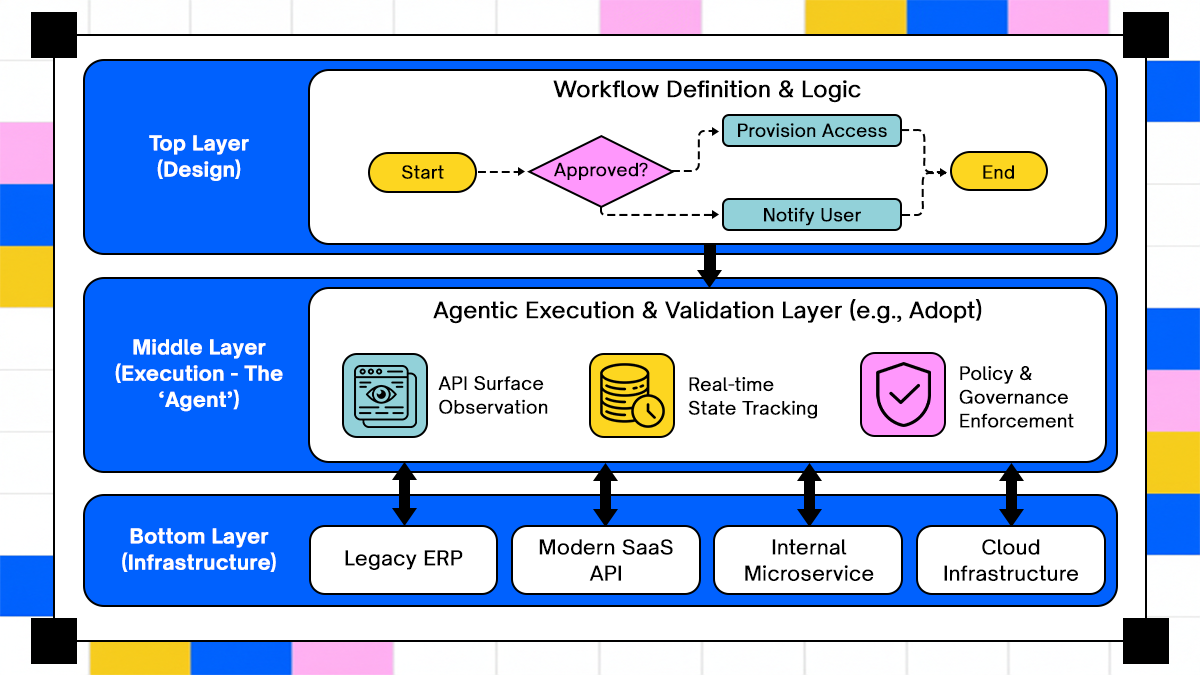
The agentic execution model inserts a validation layer that observes and interacts directly with backend APIs, ensuring workflows behave as intended under real production conditions.
Pattern: Agentic Workflow Execution
dopt observes and captures application backends’ APIs and action surfaces directly, allowing workflows to interact with systems based on their actual operational interfaces rather than predefined mappings. This capability is rooted in Adopt’s Zero Shot API Ingestion (ZAPI) process, which automatically discovers API definitions and tooling without manual engineering effort.
By extracting semantic understanding from backend behavior, workflows can execute actions across systems with greater tolerance for input and response variations. This reduces brittleness in multi-system execution, particularly where APIs differ subtly in structure or behavior across environments.
Adopt Workflow Validation And Error Handling
Traditional workflow systems validate logic at design time, assuming execution will match predefined paths. In production, this assumption often fails when systems evolve independently or return partial responses. Adopt validates the workflows using actions generated from real application behavior against live execution data to detect deviations as they occur.
Runtime monitoring highlights where workflows diverge from expected paths, such as steps that consistently take longer than anticipated or transitions that fail intermittently under load. This visibility supports targeted remediation rather than broad rollback or manual intervention.
Error handling also benefits from this execution-aware approach. Instead of relying solely on static retry rules, workflows can respond to observed outcomes, reducing the likelihood of failure loops.
Security And Compliance Context
Enterprise workflow automation operates within strict security and governance boundaries. Any execution model must respect architectural requirements that include:
- Role-based access controls that limit actions to authorized principals.
- Data residency constraints that govern where information can be processed or stored.
- Secure credential management that avoids long-lived secrets embedded in workflows.
Automated agents must integrate with existing identity and access frameworks, ensuring that actions are attributable, auditable, and compliant with organizational policy. Governance is maintained by enforcing controls at execution time rather than assuming compliance at design time.
Adopt supports these requirements through its documented action logs and external API integration patterns, which provide authenticated, traceable execution records suitable for audit and compliance workflows.
Adoption Patterns And Pitfalls
Adoption of agentic workflow execution depends on organizational readiness. Enterprises often face gaps between centralized automation teams and individual business units, leading to inconsistent workflow ownership and standards.
Common pitfalls include insufficient change management and lack of versioning discipline. Versioned workflows and clear rollback strategies are necessary to prevent regressions when logic changes or integrations evolve. Without these practices, even well-designed automation can become a source of operational risk.
Workflow Automation In The Broader Enterprise Stack
Enterprise workflow automations' behavior and reliability depend on how it integrates with adjacent layers of the enterprise stack, particularly systems that govern process definition, infrastructure operations, identity, and data movement.
Relationship To Business Process Management, IT Automation, And Service Orchestration
Workflow automation overlaps with several established enterprise disciplines, each addressing a different layer of operational complexity. Business process management focuses on modeling and optimizing business flows, often emphasizing governance and documentation over execution fidelity. IT automation concentrates on infrastructure and system-level tasks, such as provisioning or configuration changes, typically within bounded technical domains.
Service orchestration sits closer to workflow execution by coordinating interactions between services, yet it often assumes reliable inputs and deterministic behavior. Enterprise workflows span all three areas, requiring the expressiveness of process modeling, the reliability of infrastructure automation, and the coordination of orchestration, while also handling ambiguity, delay, and human decision points.
Effective workflow architectures treat these disciplines as complementary rather than interchangeable, using each where it provides structural support rather than forcing a single system to absorb all responsibilities.
Dependencies On Observability And Logging Infrastructure
Workflow automation depends heavily on observability infrastructure to remain operable over time. Logging, metrics, and tracing systems provide the raw signals required to understand how workflows progress, stall, or fail across distributed environments.
Key dependencies include centralized logging that aggregates execution data across services and time windows. Metrics pipelines that capture workflow-level signals, not only system-level performance. Distributed tracing that correlates actions across identity systems, application services, and external dependencies. Without these foundations, workflows become opaque systems in which failures surface indirectly through business impact rather than through explicit operational signals.
Integration Patterns With Identity Systems, Event Buses, And Data Lakes
Enterprise workflows integrate deeply with identity systems to enforce access controls and attribute actions to principals. Identity integration ensures that automated actions respect role boundaries and remain auditable.
Event buses provide the connective tissue for asynchronous workflows, enabling systems to publish and consume state changes without tight coupling. Data lakes serve as long-term repositories for workflow artifacts, execution logs, and audit records, supporting compliance and retrospective analysis. These integrations define how workflows move through the enterprise stack and how reliably they reflect organizational policies and operational reality.
Conclusion
This article examined how enterprises automate end-to-end workflows by treating them as distributed systems rather than isolated tasks. It explored the anatomy of enterprise workflows, the orchestration patterns that sustain them, and the failure modes that emerge when integration complexity, asynchronous execution, and scale interact.
We discussed why traditional automation approaches struggle under real conditions, how idempotence and state management shape reliability, and where observability gaps obscure operational truth. We also examined how agent-based execution models address variability, while introducing new requirements around governance, auditability, and control.
Within this landscape, Adopt AI fits as an execution-layer system that focuses on how workflows behave in production rather than how they are diagrammed at design time. For organizations evaluating workflow automation beyond pilot use cases, examining execution behavior under real constraints becomes the deciding factor for long-term reliability.
Frequently Asked Questions
1. How does Adopt fit into enterprise workflow automation architectures?
Adopt integrates at the execution layer by interacting directly with application backends and observing real workflow behavior. This allows workflows to be validated and monitored based on actual execution outcomes rather than assumed paths, which is particularly relevant in environments where systems evolve independently.
2. How can workflow observability be ensured across distributed systems?
Workflow observability requires correlating execution signals across services using shared identifiers, centralized logging, and workflow-aware metrics. Distributed tracing and explicit workflow state tracking provide visibility into progression and failure points.
3. What are best practices for rollback and exception handling?
Best practices include explicit state checkpoints, idempotent execution steps, and clearly defined escalation paths for human intervention. Rollback strategies should be versioned and tested under partial failure conditions rather than assumed to work universally.
4. How can automation speed be balanced with compliance and audit requirements?
Balancing speed and compliance depends on enforcing controls at execution time rather than relying solely on design-time validation. Role-based access, immutable audit logs, and explainable decision records allow workflows to move quickly without sacrificing accountability.

.svg)
.svg)


Take three minutes to find out which side of that line you are on.
Browse Similar Articles



Find Your Agentic AI Readiness Score
Every enterprise thinks they are building toward Agentic AI. But only few actually are.
Take three minutes to find out which side of that line you are on.












